Les composants informatiques ralentissent-ils avec le temps ? L’explication technique du vieillissement du silicium

La question revient régulièrement parmi les passionnés : les composants informatiques ralentissent-ils vraiment avec le temps ? La réponse est plus subtile qu’un simple oui ou non. Si votre vieux PC semble moins performant, la cause est souvent ailleurs, mais l’âge du silicium a un impact réel, surtout pour ceux qui poussent leurs composants.
Perte de marge de sécurité, pas de vitesse brute
Un CPU ou GPU ancien ne décide généralement pas de devenir 10% plus lent après cinq ans dans votre machine. Si un PC semble moins rapide, on peut souvent imputer cela à la poussière accumulée, à la pâte thermique qui a séché, aux logiciels en arrière-plan, au système d’exploitation plus lourd, aux patches de sécurité, aux jeux plus gourmands ou simplement à des attentes plus élevées.
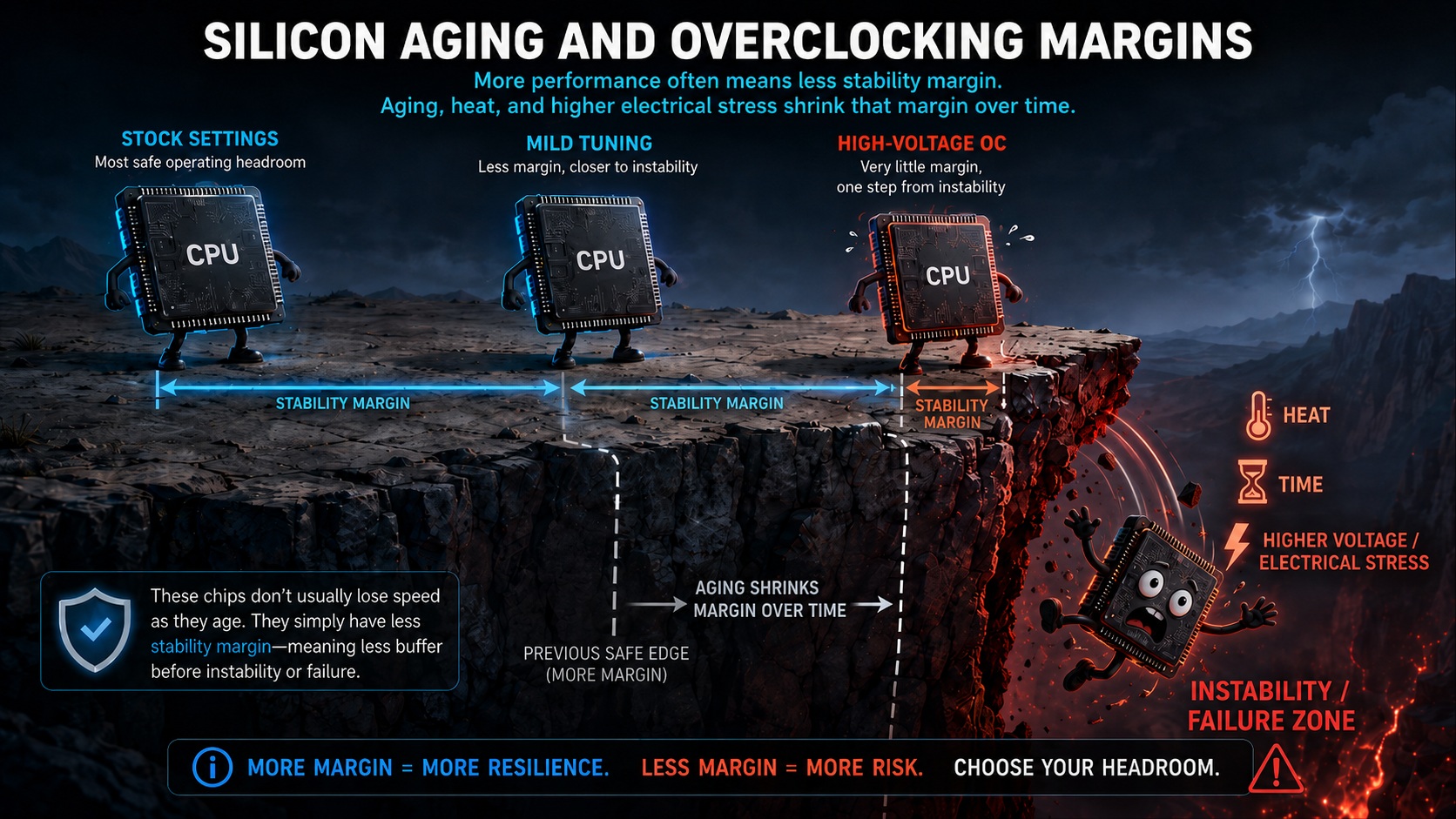
Cela ne signifie pas que l’âge du silicium est un mythe. Les transistors, les interconnexions et les chemins d’alimentation électrique subissent un stress thermique et électrique. Au fil du temps, ce stress peut réduire la marge de voltage et de fréquence qui garantissait la fiabilité du composant.

Je l’ai constaté personnellement avec des GPU sur plusieurs années. Mes cartes graphiques avaient des overclocks stables au début, puis devenaient instables avec les mêmes paramètres de fréquence, voltage et température. Elles ne devenaient pas « lentes » dans le sens traditionnel. Le wiggle-room qui rendait l’overclock possible semblait se réduire. Voilà la vraie histoire de l’âge du silicium pour les passionnés : le composant ne perd pas sa marge de sécurité qui rendait un tuning agressif possible.
Ce qui vieillit réellement dans un composant
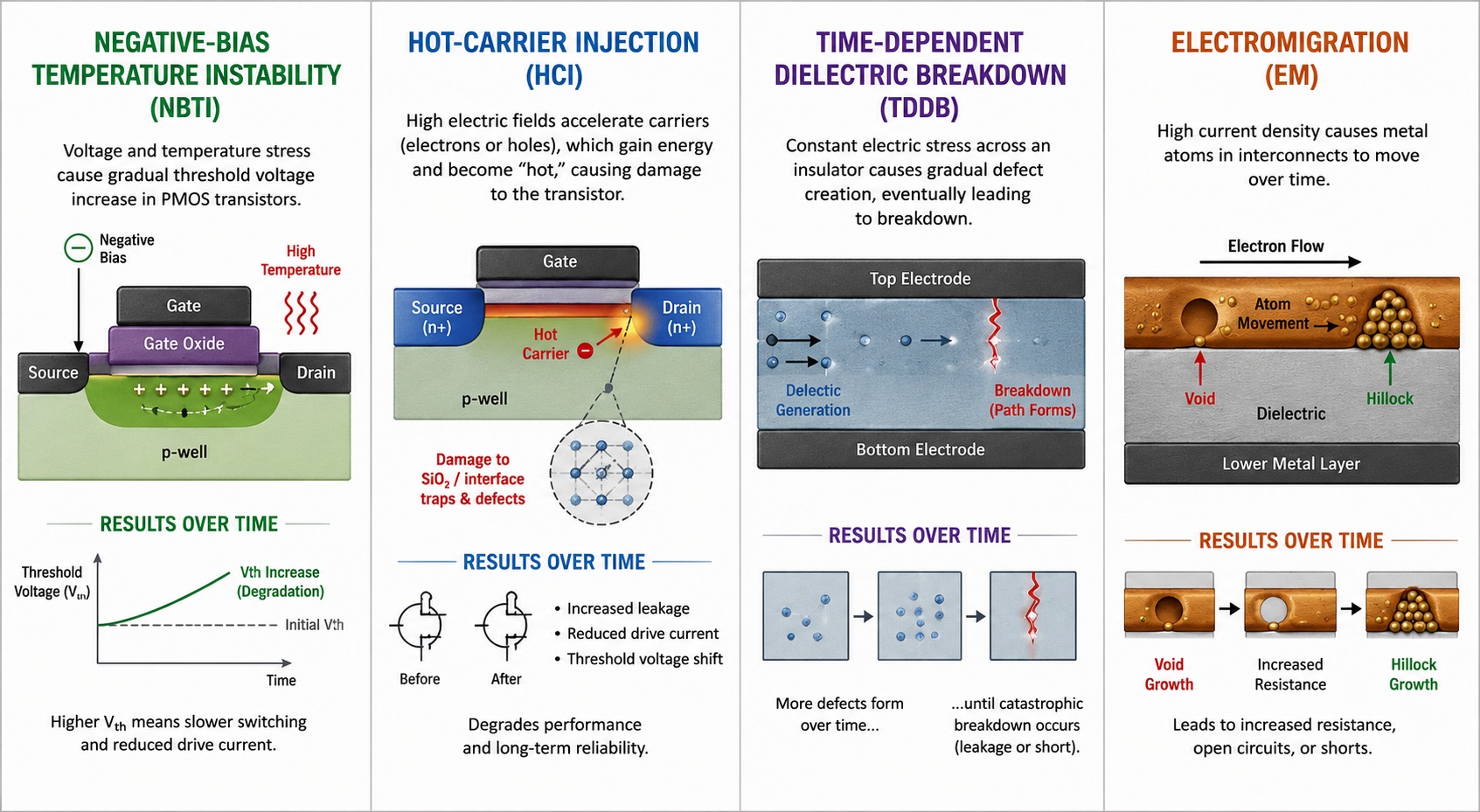
Au niveau physique, l’âge du silicium n’est pas un phénomène unique. C’est une collection de mécanismes d’usure que les ingénieurs doivent prendre en compte lors de la conception.
Les principaux mécanismes à connaître sont l’instabilité de température sous bias négatif (NBTI), l’injection de porteurs chauds (HCI), la rupture diélectrique dépendante du temps (TDDB) et l’électromigration. Une revue de 2025 sur la fiabilité des circuits intégrés identifie ces phénomènes comme des menaces majeures pour les composants qui continuent à se miniaturiser.
Le NBTI, en termes simples, signifie que le stress lié au voltage et à la température peut modifier graduellement le comportement d’un transistor. La tension de seuil peut augmenter, un transistor peut nécessiter des conditions électriques différentes pour fonctionner comme avant.
L’injection de porteurs chauds (HCI) est un autre mécanisme d’âge. Sous des champs électriques élevés, des porteurs énergétiques – des particules chargées – peuvent endommager des parties d’un transistor sur la durée.
La rupture diélectrique dépendante du temps (TDDB) concerne davantage l’usure des couches isolantes. Ce n’est généralement pas quelque chose qui cause une perte de performance progressive de 5%. C’est un mécanisme de fiabilité à long terme qui peut contribuer à une défaillance.
L’électromigration est essentiellement l’âge des connexions du composant sous stress. Les CPU et GPU contiennent de minuscules interconnexions métalliques qui transportent le courant entre les transistors. Avec le temps, une densité de courant élevée et la chaleur peuvent physiquement déplacer des atomes de métal. Cela peut créer des vide qui augmentent la résistance ou rompent une connexion.
L’âge se manifeste souvent par des crashes, pas par des baisses de performance
Les composants informatiques sont conçus autour d’une opération correcte. Un composant termine son travail à temps, ou il ne le fait pas. Un bit est correct, ou il ne l’est pas. Le composant est stable sous un voltage/fréquence/charge donné, ou il génère des erreurs, crash une application, reset un pilote ou produit des artefacts visuels.
Un benchmark de jeu peut fonctionner normalement, mais la compilation des shaders peut crash. Un GPU peut passer un test de stress léger, puis présenter un écran noir ou des artefacts dans un jeu spécifique. Un undervolt sur un CPU peut être stable pendant des mois, puis commencer à générer des erreurs WHEA. Différentes charges de travail ne stressent pas les circuits du composant de la même manière.
C’est pourquoi les passionnés du overclocking remarquent souvent l’âge du silicium plus tôt que la plupart des utilisateurs. Le overclocking réduit la marge entre un composant stable et un composant instable. Si un GPU en configuration stock a beaucoup de wiggle-room, un vieillissement léger peut ne pas être visible.
Intel Raptor Lake : quand l’âge du silicium devient un problème mainstream
Le meilleur exemple récent de ce problème touchant le marché PC mainstream est l’instabilité des CPU desktop Intel Core 13e génération (Raptor Lake) et 14e génération (Raptor Lake Refresh).
Des utilisateurs ont rapporté des crashes sur ces CPU haut de gamme. Le problème apparaissait principalement dans les jeux utilisant l’Unreal Engine 5 d’Epic, spécifiquement durant les phases de compilation/décompression des shaders/PSO utilisant la bibliothèque propriétaire Oodle de RAD Game Tools. Intel a finalement lié le problème à un voltage de fonctionnement élevé et ce qu’ils ont appelé l’Instabilité du Shift Vmin. En octobre 2024, des rapports basés sur l’update d’Intel indiquaient que la compagnie avait identifié un voltage excessif et un vieillissement prématuré comme partie de la cause racine.
Voilà un cas d’étude qui rend l’âge du silicium plus facile à comprendre pour les passionnés. Vmin désigne le voltage minimum requis pour une opération stable dans une condition donnée. Si ce voltage minimum augmente, le composant peut nécessiter plus de voltage qu’avant pour rester stable à la même fréquence.
Le point clé ici n’est pas que chaque CPU Raptor Lake était condamné. La leçon est plus spécifique : si le comportement du voltage devient problématique, et si un composant est exposé à un voltage et une température élevés suffisamment longtemps, l’âge du silicium peut devenir un problème visible pour le consommateur.
Il est aussi important de se souvenir que les mitigations logiciels et firmware ne peuvent inverser magiquement la dégradation physique du silicium. Les reports sur les corrections d’Intel clarifiaient que les updates pouvaient aider à prévenir des dommages futurs, mais les CPU déjà dégradés nécessiteraient généralement un remplacement plutôt qu’une solution miracle via BIOS/microcode.

Overclocking : utiliser aujourd’hui la marge de sécurité de demain
L’overclocking est plaisant parce qu’il utilise un wiggle-room caché pour le transformer en performance supplémentaire, au prix de chaleur/puissance additionnelles et d’une instabilité potentielle. Mais c’est aussi pourquoi l’overclocking est un des moyens les plus simples pour exposer l’âge du silicium.
Un composant en configuration stock est validé pour fonctionner dans une enveloppe d’opération définie qui prend en compte le voltage, le courant et la thermique. Cette enveloppe inclut des suppositions de fiabilité. Quand vous augmentez le voltage, débloquez les limites de puissance, utilisez un calibrage de ligne de charge élevé, maintenez des températures élevées, ou poussez les fréquences hors spécifications, vous vous rapprochez de la limite.
Un offset léger sur la fréquence du cœur d’un GPU, un undervolt prudent ou un overclock quotidien raisonnable pour un CPU peut être tout à fait raisonnable. Mais un voltage élevé est différent. Le voltage a un effet disproportionné sur la dégradation à long terme parce qu’il augmente directement le stress du champ électrique dans le composant. Combine cela avec la chaleur et le temps, et vous avez une recette classique pour un vieillissement accéléré du silicium.
Voilà pourquoi « il a passé un test de stress » n’est pas la même chose que « ce sera stable pendant cinq ans. » Un overclock stable dans plusieurs benchmarks et tests de stress peut avoir presque aucune marge à long terme. Le fait qu’il fonctionne aujourd’hui ne signifie pas qu’il continuera à fonctionner durablement.
Une façon utile de le concevoir : les configurations stock demandent si le composant peut fonctionner de façon fiable pendant des années. L’overclocking demande à quelle distance du précipice vous pouvez vous tenir maintenant. Et parfois, après des mois ou des années de chaleur, voltage et utilisation intense, le bord de ce précipice se rapproche.
La version de démystification
Le premier mythe est que les anciens CPU et GPU ralentissent automatiquement chaque année. En général, ils ne le font pas. Un CPU de cinq ans fonctionnant aux mêmes fréquences, limites de puissance, voltages, thermiques et dans le même environnement logiciel ne devrait pas perdre de performance simplement parce que le temps a passé.
Le second mythe est que l’âge du silicium est faux – il n’est pas faux. Les architectes et ingénieurs de composants prennent en compte l’âge parce que les mécanismes NBTI, HCI, TDDB et électromigration sont des mécanismes de fiabilité réels.
Le troisième mythe est que toute baisse de score de benchmark prouve que votre composant est dégradé, mais généralement, ce n’est pas le cas. Le comportement de boost de fréquence des composants modernes est extrêmement sensible aux températures, voltages, limites de puissance/courant, paramètres BIOS/UEFI, tâches en arrière-plan, pilotes système et même à la température ambiante.
Le quatrième mythe est que l’undervolt est dangereux. Un undervolt raisonnable peut réduire le voltage, la chaleur et la consommation électrique, ce qui peut être bénéfique pour la longévité de votre composant. Le risque n’est pas l’undervolt lui-même ; le risque est de réduire trop le voltage et créer de l’instabilité.
Le cinquième mythe est que la dégradation due au overclock est toujours un placebo. Elle n’est pas. Si un composant tenait un certain overclock à un certain voltage et température, et qu’il ne peut plus le tenir ensuite dans des conditions comparables, alors une perte de marge de stabilité est une explication réaliste.

Comment garder un composant informatique en bonne santé plus longtemps ?
Garder un composant informatique de type consommateur (CPU ou GPU) en bonne santé plus longtemps implique de suivre un ensemble de règles simples et sensées.
Premièrement, ne fonctionnez pas avec plus de voltage que nécessaire. Contrôlez les températures. Ne faites pas confiance sans vérification aux configurations stock agressives de la carte mère, particulièrement sur les CPU haut de gamme. Maintenez le BIOS et le microcode à jour quand les constructeurs identifient des problèmes de stabilité ou de longévité. Re-testez les anciens overclocks occasionnellement au lieu de supposer qu’un profil d’OC de 2022 restera stable pour toujours.
Pour les GPU, vérifiez les points basiques : présence de poussière, application de la pâte thermique, pads thermiques sur les chips de mémoire du GPU, températures du cœur/mémoire du GPU, stabilité du PSU et comportement des pilotes. Pour les CPU, vérifiez les paramètres BIOS/UEFI, températures, courbes voltage/fréquence, limites puissance/courant, stabilité de la mémoire système, undervolts et votre solution de cooling avant de supposer que le silicium lui-même est endommagé.
Et si un CPU ou GPU devient instable en configuration stock après que les variables de cooling, mémoire système/GPU, PSU, BIOS/UEFI et logiciels ont été exclues, il est raisonnable de penser à la garantie ou au remplacement. Une instabilité en configuration stock n’est pas quelque chose que les utilisateurs devraient contourner.

Conclusion
La vieille question hante chaque passionné de PC : les composants informatiques ralentissent-ils réellement avec l’âge ?
Pour la plupart d’entre nous, la réponse courte est non. Contrairement à une batterie de smartphone, un CPU ou GPU ne perd pas simplement 2% de sa performance chaque année. Si votre machine de jeu semble moins rapide, ne blâmez pas le silicium ; blâmez la pâte thermique qui a séché, les logiciels gonflés ou les jeux modernes plus gourmands.
Mais la dégradation du silicium est réelle. Des années de voltage élevé, de chaleur et de charges de travail intense réduisent graduellement la marge de stabilité du composant. En configuration stock, cette marge est large, et vous ne remarquerez probablement jamais d’instabilité, à moins d’utiliser le composant pendant une décennie !
Cependant, si vous avez utilisé des overclocks agressifs, des voltages auto élevés de la carte mère ou un cooling pauvre, cette marge de sécurité se réduit, et rapidement. Quand cette marge disparaît, votre hardware ne perd pas simplement quelques fps. Il fait des caprices. Ce GPU overclocké ou CPU undervolté autrefois stable crash vos applications et jeux, génère des erreurs WHEA, des resets de pilotes, des failures de décompression et des écrans bleus/noirs aléatoires sous charge. Le vieux hardware ne ralentit pas gracieusement. Il « perd sa patience » et devient moins indulgent avec vos réglages fins.



