La RTX PRO 6000 96 Go de NVIDIA égale 4 RTX 5090 sur un modèle IA de 230 milliards tout en consommant 4x moins

De nouveaux tests maison opposent une unique RTX PRO 6000 Blackwell à des configurations grand public en multi-cartes. Un seul GPU Blackwell approche les performances de quatre RTX 5090 pour l’inférence d’un modèle 230B tout en divisant la consommation par quatre. De quoi remettre en question les rigs multi-GPU pour faire tourner de gros modèles d’IA chez soi.
Contexte et méthodologie de test
La NVIDIA RTX PRO 6000 Blackwell montre qu’un seul GPU peut surpasser des montages multi-cartes grand public pour exécuter de grands modèles d’IA, au point de rivaliser avec un pack de quatre RTX 5090.
Une seule RTX PRO 6000 Blackwell exécute un modèle IA 230B avec un quart de la puissance de quatre RTX 5090
Sur X, stevibe a partagé des mesures issues de sa batterie de tests pour vérifier s’il est réaliste de faire tourner de très grands modèles chez soi. Pour la démo, il a choisi MiniMax M2.7, un modèle d’inférence de 230B paramètres, et l’a testé sur quatre configurations propulsées par des GPU NVIDIA, avec un contexte de 32k et une longueur maximale de 4096 tokens.
MiniMax M2.7 is 230B params. Can you actually run it at home?
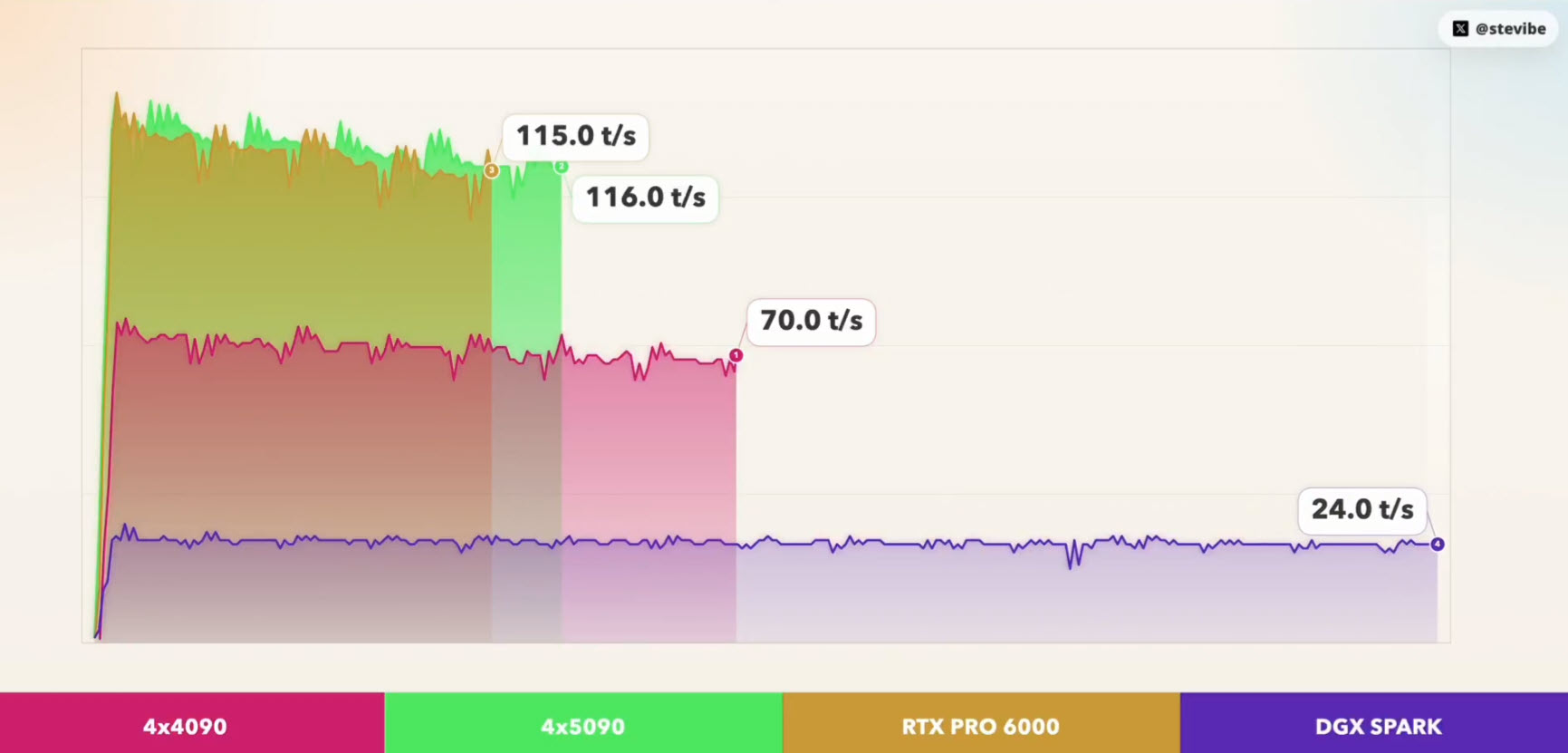
I tested Unsloth’s UD-IQ3_XXS (80GB) on 4 different rigs:
🟠 4x RTX 4090 (96GB): 71.52 tok/s, TTFT 1045ms
🟢 4x RTX 5090 (128GB): 120.54 tok/s, TTFT 725ms
🟡 1x RTX PRO 6000 (96GB): 118.74 tok/s, TTFT 765ms
🟣 DGX… pic.twitter.com/yK8bGg6RtX— stevibe (@stevibe) April 18, 2026
L’auteur précise avoir utilisé IQ3_XXS, une quantization GGUF adaptée aux cartes à plus faible VRAM, et surtout le plus gros quant qui tient dans les 96 Go de VRAM du GPU RTX PRO 6000. La même quantization a été appliquée aux quatre configurations, et voici les résultats:
- 4x RTX 4090 (96GB): 71.52 tok/s, TTFT 1045ms
- 4x RTX 5090 (128GB): 120.54 tok/s, TTFT 725ms
- 1x RTX PRO 6000 (96GB): 118.74 tok/s, TTFT 765ms
- DGX Spark (128GB): 24.41 tok/s, TTFT 741ms
En débit de génération de tokens, la RTX PRO 6000 Blackwell seule atteint 118.74 tok/s. À titre de repère, quatre RTX 5090 totalisant 128 Go culminent à 120.54 tok/s, tandis que quatre RTX 4090 (4 × 24 Go) se placent à 71.52 tok/s. Le mini PC IA DGX Spark affiche 24.41 tok/s avec 128 Go de mémoire.
Comparer le débit ne raconte que la moitié de l’histoire. Il faut aussi regarder la consommation et le coût.
Côté énergie, l’écart se creuse. Les montages à quatre cartes tirent 1800 W et 2300 W respectivement pour les RTX 4090 et RTX 5090. Une seule RTX PRO 6000 Blackwell se contente de 600 W.
- 4×4090 → 1,800W en pic (450W × 4)
- 4×5090 → 2,300W en pic (575W × 4)
- RTX PRO 6000 → 600W en pic
- DGX Spark → 240W en pic (système complet)
On parle d’un quart de la consommation des quatre RTX 5090 et d’environ un tiers face aux quatre 4090. Le DGX Spark reste à 240 W pour l’ensemble de la machine, intéressant pour un boîtier compact présenté comme « prefill-friendly » et alimenté sur une simple prise murale.
Côté tarif, une RTX PRO 6000 Blackwell tourne autour de 9500 €, quand une RTX 5090 coûte environ 3500 € pièce. Quatre 5090 reviennent donc à 14000 €. Le DGX Spark est proposé à 4699 € après hausse.
- Prix moyen RTX 4090 en boutique – 3000 € (par GPU)
- Prix moyen RTX 5090 en boutique – 3500 € (par GPU)
- Prix moyen RTX PRO 6000 en boutique – 9500 € (par GPU)
- Prix moyen DGX Spark AI PC – 4699 €
Les modèles d’IA peuvent tirer parti de plusieurs GPU et additionner leur mémoire, mais la répartition et les échanges introduisent des surcoûts et des latences, visibles ici. Avec ses 96 Go, une RTX PRO 6000 Blackwell unique contourne ces limites et offre de meilleures performances par watt, avec un coût plus cohérent que les montages multi-cartes grand public.



