OpenAI réunit AMD, NVIDIA, Intel, Microsoft et Broadcom pour accélérer l’entraînement IA à grande échelle – Tous à fond sur MRC

OpenAI réunit AMD, NVIDIA, Intel, Microsoft et Broadcom pour booster l’entraînement des modèles d’IA à grande échelle. Le groupe dévoile le protocole MRC, qui optimise les réseaux de GPU dans les clusters géants. Disponible via l’Open Compute Project, il promet plus de fiabilité face aux pannes et congestions.
Les défis des réseaux pour l’IA massive
Ce partenariat forme un réseau de superordinateurs dédié à l’accélération des entraînements massifs. Les entreprises collaborent sur MRC (Multipath Reliable Connection), un protocole qui renforce les performances et la robustesse des connexions GPU dans les grands ensembles.
OpenAI publie aujourd’hui MRC au sein de l’OCP pour une adoption large par le secteur de l’IA.
Le souci principal réside dans les transferts de données lors des entraînements de gros modèles. Un seul retard peut bloquer tout le processus et laisser les GPU inactifs. Les causes : congestions réseau, pannes de liens ou d’équipements. Plus le cluster grandit, plus ces incidents se multiplient.
MRC constitue la base des superordinateurs next-gen pour l’IA à grande échelle. OpenAI a coopéré deux ans avec AMD, Broadcom, Intel, Microsoft et NVIDIA sur ce protocole, intégré aux interfaces réseau 800 Gb/s récentes. Les entreprises d’IA peuvent ainsi répartir un transfert sur des centaines de chemins sans interruption, contourner les pannes en microsecondes et simplifier les plans de contrôle réseau.
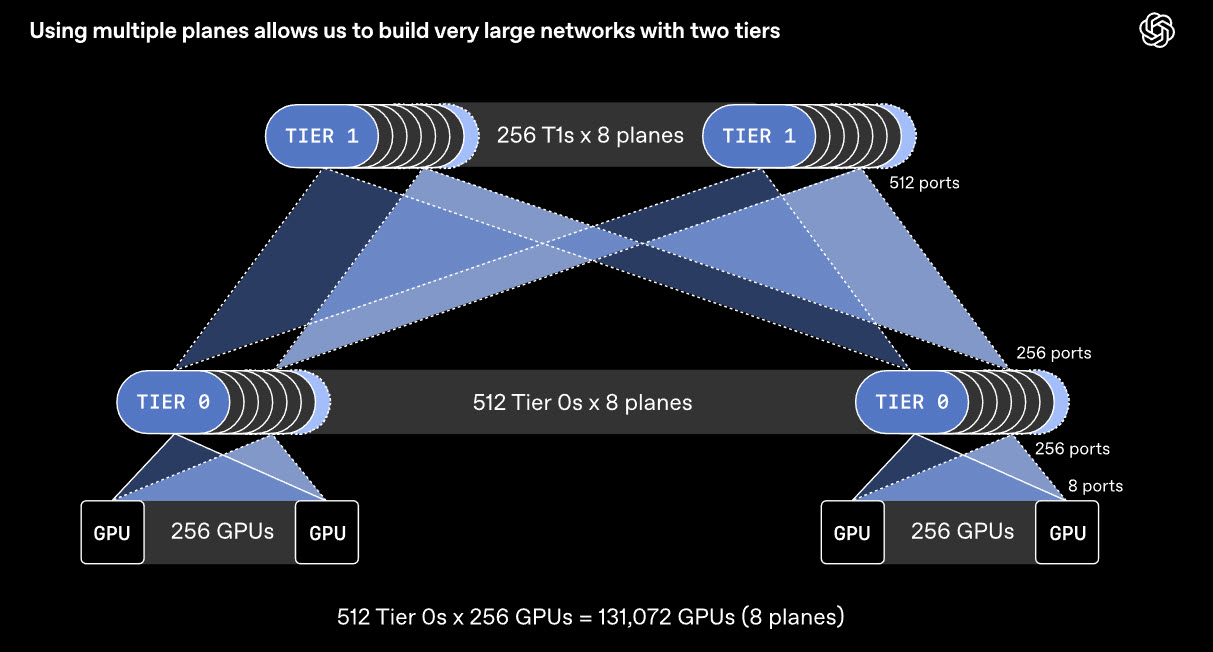
Plutôt que de voir une interface réseau comme un lien unique de 800 Gb/s, nous la divisons en plusieurs liens plus petits. Par exemple, une interface peut se connecter à huit commutateurs distincts. Cela permet de créer huit réseaux parallèles, ou plans, chacun à 100 Gb/s, au lieu d’un seul réseau 800 Gb/s.
Ce choix modifie profondément l’architecture du cluster. Un commutateur pour 64 ports à 800 Gb/s gère alors 512 ports à 100 Gb/s. Résultat : un réseau reliant environ 131 000 GPU avec seulement deux niveaux de commutateurs. Un réseau classique 800 Gb/s en exigerait trois ou quatre.
OpenAI
Le standard MRC étend RDMA sur RoCE (Converged Ethernet), avec accélération matérielle pour l’accès distant à la mémoire des GPU et CPU. OpenAI l’a déjà déployé sur ses superordinateurs équipés des GPU NVIDIA GB200 « Blackwell » pour entraîner les modèles Frontier, dont ceux d’Oracle Cloud Infrastructure à Abilene, Texas, et les superordinateurs Fairwater de Microsoft.

MRC a servi à entraîner plusieurs modèles OpenAI sur matériel NVIDIA et Broadcom. Ce protocole jouera un rôle clé dans le superordinateur Stargate d’OpenAI, construit par Oracle Cloud Infrastructure à Abilene, Texas. Prévu pour 10 GW de calcul IA d’ici 2029, le site a déjà mis en service plus de 3 GW ces trois derniers mois. Ouvert à tout le secteur, MRC favorise les collaborations pour relever les défis les plus complexes de l’IA.



