NVIDIA triple les perfs du path tracing avec des algorithmes ReSTIR améliorés pour le gaming next‑gen

NVIDIA présente une version peaufinée de ReSTIR qui accélère le Path Tracing d’un facteur 2 à 3. De quoi donner un vrai coup de fouet aux jeux PC, où le rendu intégralement tracé par rayons reste coûteux sur le matériel actuel. Les premiers chiffres annoncent des gains nets, moins de bruit visuel et une baisse de l’empreinte mémoire. Le géant compte aussi s’appuyer sur l’IA pour pousser plus loin les optimisations côté GPU.
Le Ray Tracing, c’est bien, mais le Path Tracing va plus loin, et NVIDIA rend le PT jusqu’à 3x plus rapide avec ses nouveaux algorithmes ReSTIR
Le Path Tracing gagne du terrain pour offrir un rendu nouvelle génération sur PC. Comme pour le Ray Tracing à ses débuts, NVIDIA a ouvert la voie sur ordinateur. Mais la difficulté reste la même: il faut du matériel très rapide. On l’a vu sur plusieurs titres PT, où même une RTX 5090 plafonne souvent à 30-40 FPS et s’appuie lourdement sur le suréchantillonnage DLSS et la génération d’images pour atteindre une cadence jouable.
Le Ray Tracing a suivi un parcours similaire: d’abord sur PC, puis des performances aujourd’hui correctes sur le matériel moderne. Les consoles l’embarquent aussi de plus en plus, généralement via des préréglages Qualité qui tournent à 30 FPS, parfois 60 FPS dans quelques cas.

NVIDIA, pionnier du rendu temps réel sur PC, passe à l’étape suivante pour le Path Tracing. Dans un nouveau papier de recherche intitulé « ReSTIR PT Enhanced: Algorithmic Advances for Faster and More Robust ReSTIR Path Tracing », l’entreprise détaille une série d’algorithmes de rééchantillonnage spatio-temporel capables d’offrir un gain de 2 à 3x tout en limitant les artefacts visuels propres aux méthodes RT/PT actuelles.

La solution présentée serait proche d’un état « production ready » et divise par deux le coût de réutilisation spatiale. Les algorithmes ReSTIR PT Enhanced améliorent à la fois performances et qualité grâce à des optimisations qui unifient l’illumination directe et globale, tout en s’appuyant sur des techniques existantes pour réduire le bruit de couleur et le bruit de désocclusion. Liste des évolutions :
- Division par deux du coût de « shift mapping » en réutilisation spatiale via une sélection réciproque des voisins
- Nouveaux seuils d’empreinte de rayon qui s’adaptent à la scène et aux matériaux
- Réduction des corrélations grâce à des cartes de duplication d’exemplaires
- Amélioration qualité/coût en unifiant ReSTIR pour la lumière directe et indirecte
- Autres optimisations renforçant les performances et la robustesse en réduisant le bruit de couleur et de désocclusion
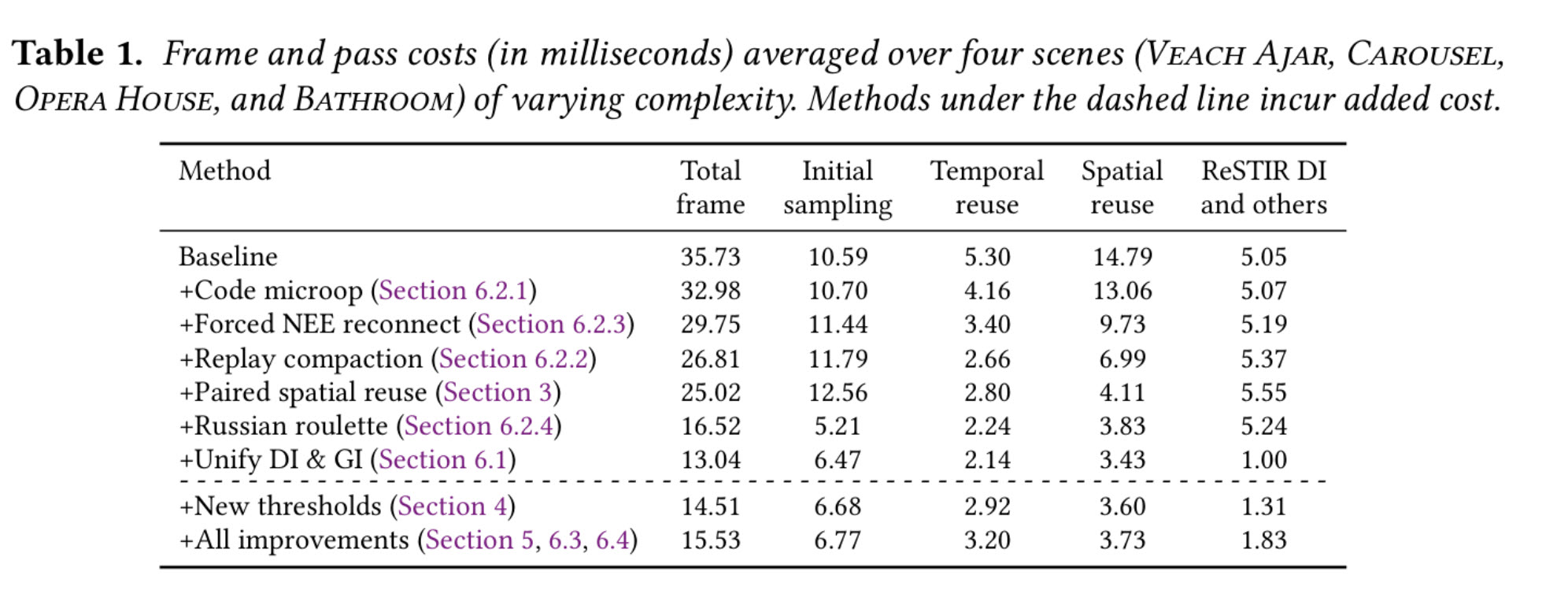
Le Tableau 1 présente les performances de nos techniques, chaque ligne ajoutant une nouvelle optimisation par-dessus la base issue du code public de Lin et al. [2022]. Nous mesurons d’abord le gain apporté par nos réductions de coût, qui offrent en moyenne un accélérateur de 2,74× sur les quatre scènes testées. Les scènes ont été choisies pour couvrir des géométries et des matériaux variés. Les résultats scène par scène figurent dans le matériel complémentaire.
Pour mieux cerner l’impact de nos optimisations bas niveau côté GPU, nous avons profilé Opera House avec NSight Graphics. Les données indiquent que les optimisations des sections 6.2.1–6.2.3 réduisent la divergence des threads et améliorent l’efficacité de calcul. Concrètement :
- Occupation des warps SM de 22,4% → 31,1%
- Threads actifs par warp de 15,3 → 19,9
- Latence des warps de 347k → 241k cycles
Tout ceci sans modifier le comportement de l’échantillonneur. L’application de la roulette russe (Section 6.2.4) améliore encore ces métriques jusqu’à :
- 34,9% d’occupation
- 20,6 threads actifs par warp
- 82k cycles de latence
Notre méthode réduit aussi l’empreinte mémoire par rapport à la base via deux changements: compression du réservoir ReSTIR PT et unification des réservoirs pour l’éclairage direct et indirect. Chaque passe ReSTIR nécessitant deux ensembles de réservoirs pour la réutilisation temporelle, on passe de 2 × (88 + 16) octets dans l’implémentation de référence (qui emploie des réservoirs de 16 octets pour ReSTIR DI) à 2 × 64 octets. En 1920×1080, la consommation mémoire chute de 431 MB à 265 MB.
Résultats d’optimisation GPU comparés à Lin et al. [2022]
Technique / Étape Occupation des warps SM (%) Threads actifs par warp Latence des warps (cycles) Accélération vs. base Notes Base (Lin et al. [2022]) 22.4 15.3 347k 1.0× Code public de référence Optimisations GPU bas niveau (Sec. 6.2.1–6.2.3) 31.1 19.9 241k 2.74× (moy. sur 4 scènes) Divergence réduite, efficacité accrue + Roulette russe (Sec. 6.2.4) 34.9 20.6 82k — Gains d’efficacité supplémentaires + Nouveaux seuils (Sec. 4, 5, 6) — — — — Critères de reconnexion indépendants des scènes, meilleure qualité du shift mapping Toutes améliorations (décorrélation, réduction du bruit) — — — 2.30× Ajoute 19% de coût vs. la version la plus rapide, mais reste plus rapide que la base
Bonne nouvelle pour le Path Tracing: NVIDIA pousse les performances depuis l’arrivée des GPU RTX 40 et RTX 50. Prochaine étape, multiplier les techniques de Neural Rendering et les algorithmes d’IA pour peaufiner encore le rendu et tirer plus de performances des cartes de jeu.



