Intel lance son Texture Set Neural Compression SDK : textures jusqu’à 18x plus petites

Intel passe à la vitesse supérieure avec la compression neuronale des textures et en fait un vrai outil pour les studios. Présentée à la GDC 2026, la solution promet des gains de stockage et de mémoire sans sacrifier la fidélité, jusqu’à pouvoir décoder par pixel en temps réel. De quoi optimiser les textures dans les jeux tout en restant compatible avec des moteurs et matériels variés. Une version Alpha du SDK arrive cette année.
TSNC par Intel : ce qu’il faut retenir
À la GDC 2026, l’ingénieure graphique Marissa Dubois est montée sur scène pour dévoiler la version d’Intel de la compression neuronale des textures, très proche de la NTC de NVIDIA par son caractère déterministe. Suite directe du prototype de R&D présenté à la GDC 2025, la nouveauté majeure tient au passage en produit avec un SDK autonome prêt à intégrer les moteurs.
Texture Set Neural Compression (TSNC) propose une méthode plus intelligente pour stocker les textures. Les formats de compression par blocs du GPU (BC1 à BC7) reposent sur des règles fixes, rapides et universellement supportées, mais ils laissent encore beaucoup d’efficacité sur la table. TSNC adopte une autre stratégie : entraîner un petit réseau neuronal via descente de gradient stochastique pour apprendre à encoder et décoder un ensemble donné de textures. On obtient une représentation compacte en espace latent qu’un MLP minimaliste reconstruit à l’exécution en données diffuses, normales, rugosité, métalliques, AO et émissives.
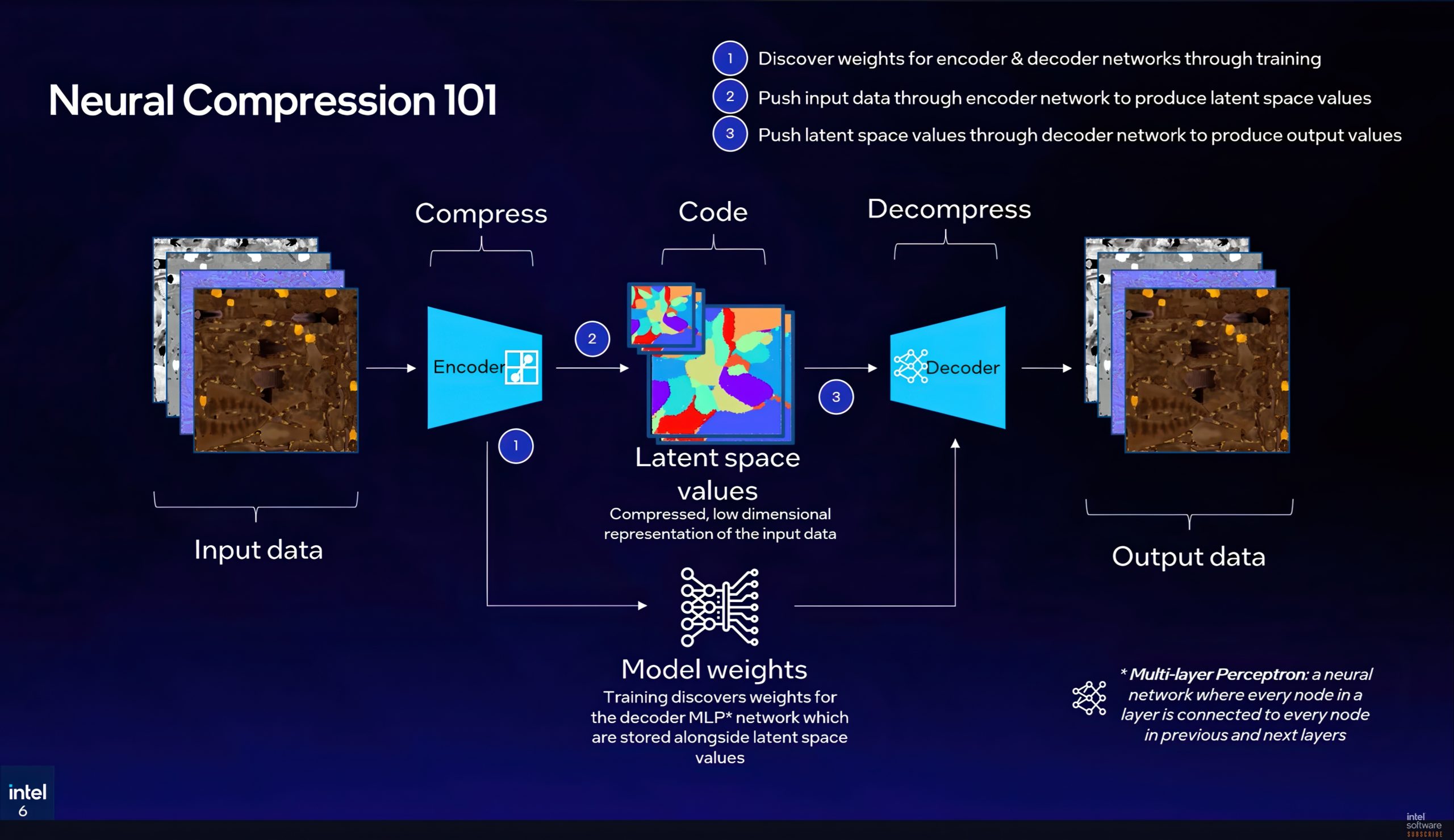
L’idée clé : un set de textures (toutes les cartes PBR d’un même matériau) partage énormément de structure redondante entre ses canaux. TSNC exploite ces corrélations que la compression par blocs générique ne sait pas capter.
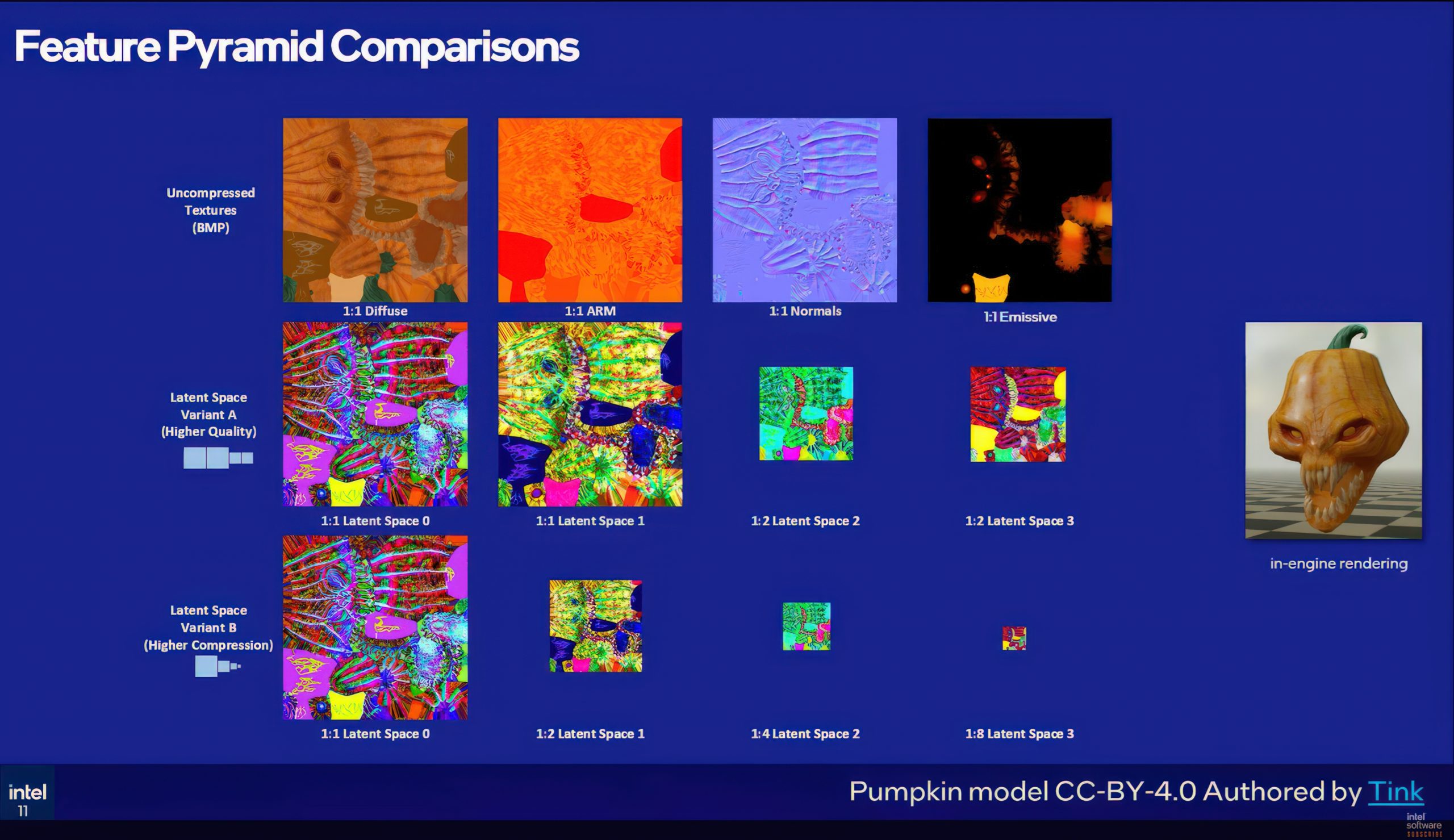
Pyramides de features : deux paliers
Le cœur du schéma de compression TSNC est la pyramide de features, un jeu de quatre textures latentes encodées en BC1 à des résolutions différenciées. Intel propose actuellement deux variantes offrant des compromis qualité/ratio distincts :
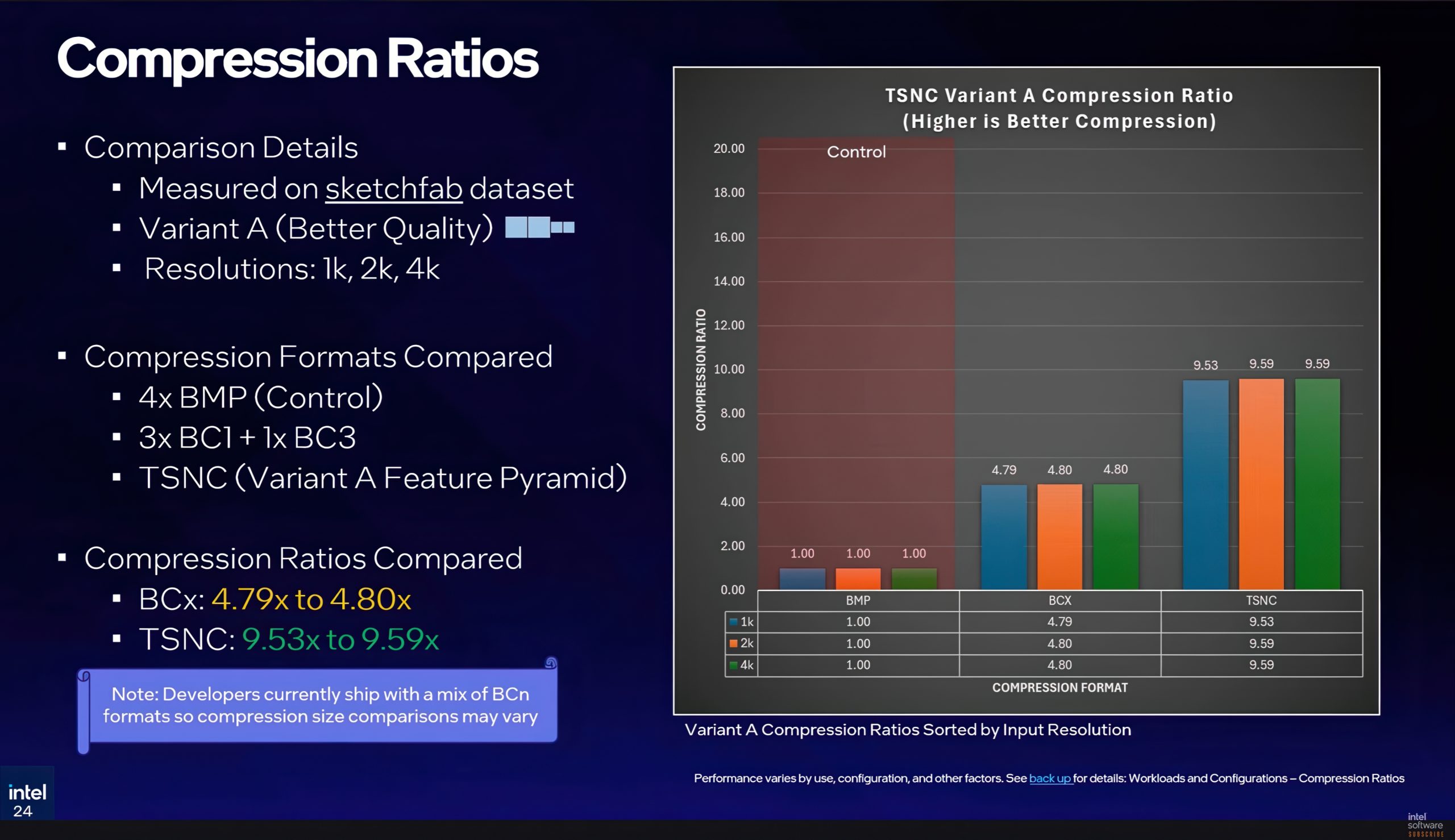
- Variant A utilise deux images latentes en pleine résolution et deux en demi-résolution. Pour des textures 4K, on obtient deux 4K et deux 2K, pour environ 26,8 Mo contre 256 Mo en bitmaps non compressés. On parle de plus de 9x de compression, presque le double des 4,8x d’un BC classique. La perte perceptive mesurée avec l’outil FLIP de NVIDIA tourne autour de 5 %, se traduisant surtout par une précision un peu moindre sur les normales, le reste demeurant discret.
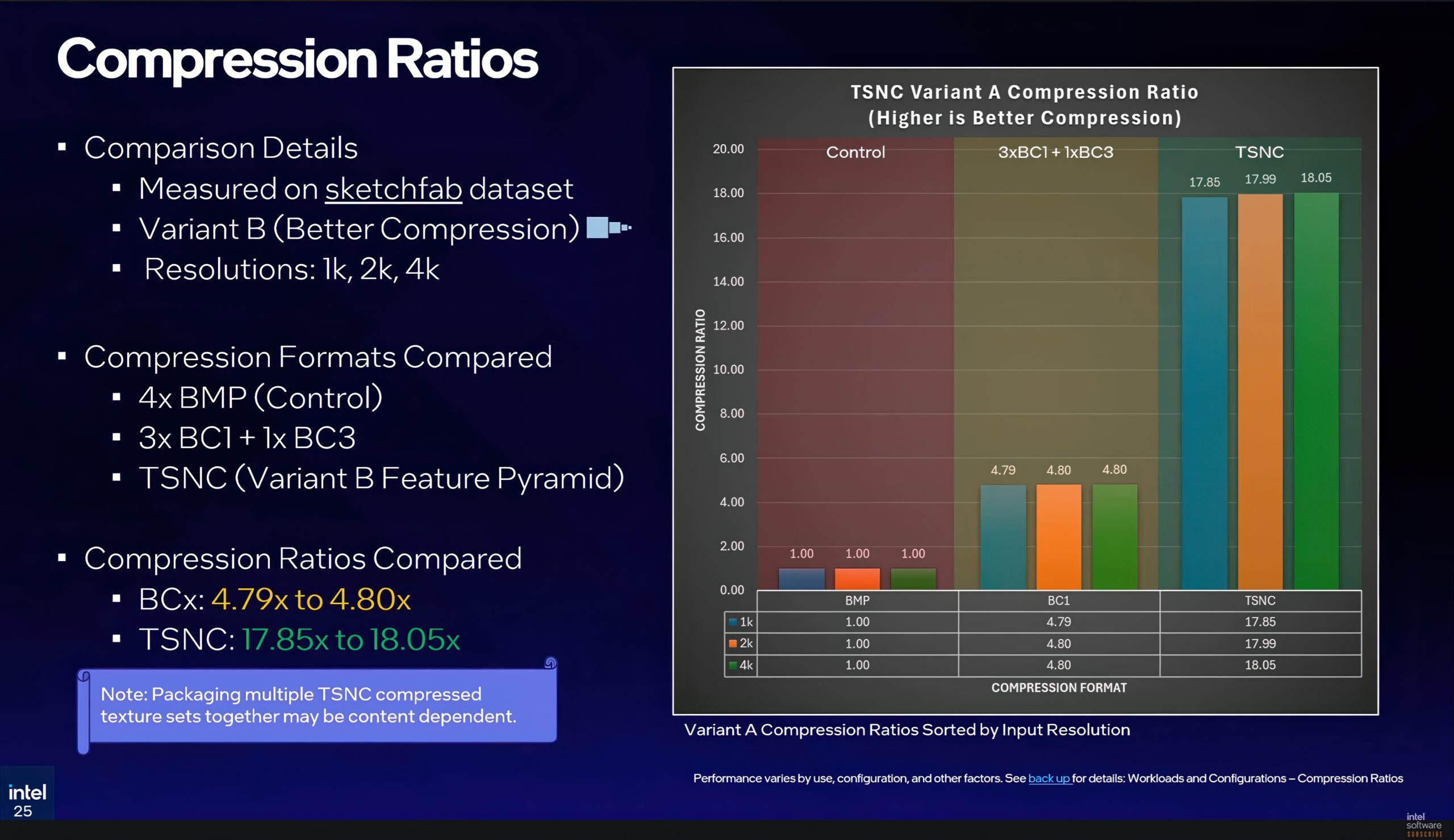
- Variant B est plus agressive. Les images latentes décroissent à 1/2, 1/4 et 1/8 de la résolution d’origine, pour plus de 17x de compression, soit plus du double de la Variant A. En contrepartie, les artefacts BC1 deviennent visibles dans les cartes de normales et les canaux AO/rugosité, avec une erreur FLIP d’environ 6–7 %. La différence reste modérée en valeur absolue, mais assez présente pour être perçue. La Variant B convient mieux aux matériaux lointains ou secondaires, moins scrutés.
Depuis le prototype R&D de l’an dernier, initialement en PyTorch, tout le compresseur Texture Set Neural Compression a été réécrit de zéro en shaders compute Slang. Quelle que soit la cible (Unreal, moteur maison ou décompression sur CPU), le même code de décompression peut viser le backend approprié.
Côté GPU, Intel prend désormais en charge l’API DirectX 12 Cooperative Vectors de Microsoft, en s’appuyant sur les cœurs matriciels XMX des Intel Arc (séries A et B) pour accélérer l’inférence. Sur un matériel sans XMX, une voie de repli FMA (fused multiply-add) fonctionne sur CPU et sur des GPU non‑Intel.
Marissa Dubois a détaillé quatre stratégies de déploiement, avec des équilibres différents entre taille disque et usage mémoire :
- À l’installation — livrer compressé, décompresser localement pendant l’installation. Les textures résident en clair sur le disque de l’utilisateur. Gain surtout sur la bande passante de distribution.
- Au chargement — les textures restent compressées sur disque ; décompression vers la VRAM pendant le chargement du jeu. Réduit l’empreinte à l’installation et la pression VRAM lors des chargements.
- Au streaming — combiné au streaming de textures, décompression à la demande. Bon compromis disque/mémoire, avec un coût d’inférence en runtime.
- À l’échantillonnage — les textures restent compressées en VRAM de façon permanente et sont décodées par pixel dans le shader. Option la plus agressive pour économiser la VRAM, avec un coût d’inférence constant.
Les studios choisiront l’approche la plus adaptée à leur pipeline et à leur moteur.
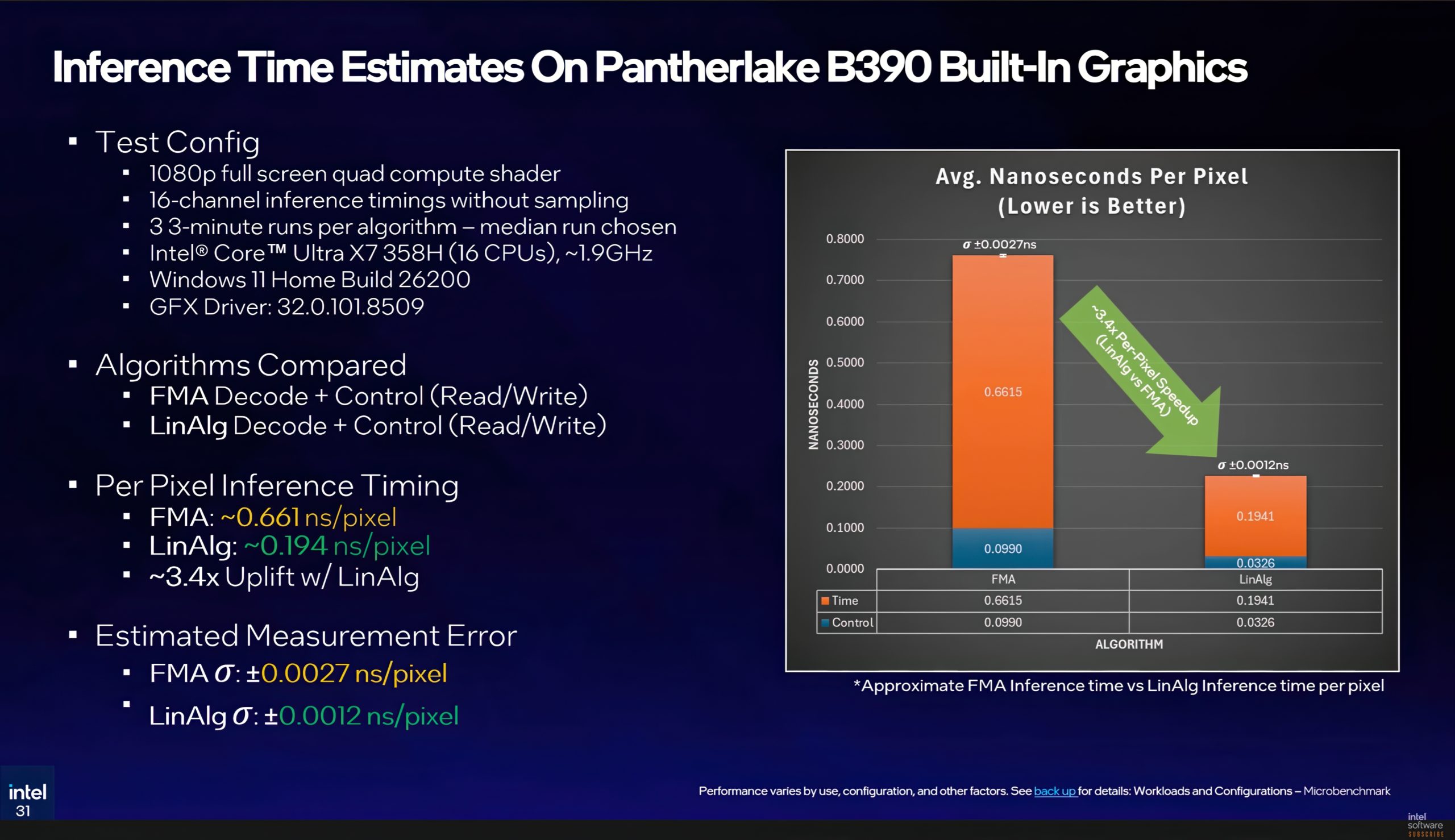
Intel a mesuré l’inférence sur un portable Panther Lake avec iGPU B390 sous une charge compute 1080p complète. Résultats :
- Voie FMA : 0,661 nanoseconde par pixel
- Voie XMX linéaire algébrique : 0,194 nanoseconde par pixel
Soit un gain de 3,4x grâce aux opérations matricielles accélérées, avec des chiffres déjà solides sur un iGPU, ce qui rend crédible le décodage par pixel à l’échantillonnage. Sur des GPU dédiés, la surcharge serait encore moindre. Intel prévoit de publier une version Alpha du SDK Texture Set Neural Compression plus tard cette année, suivie d’une bêta puis d’une sortie publique, mais ces dates restent à préciser.



