Évolution de l’IA: des règles codées à la main à l’IA générative et aux agents autonomes
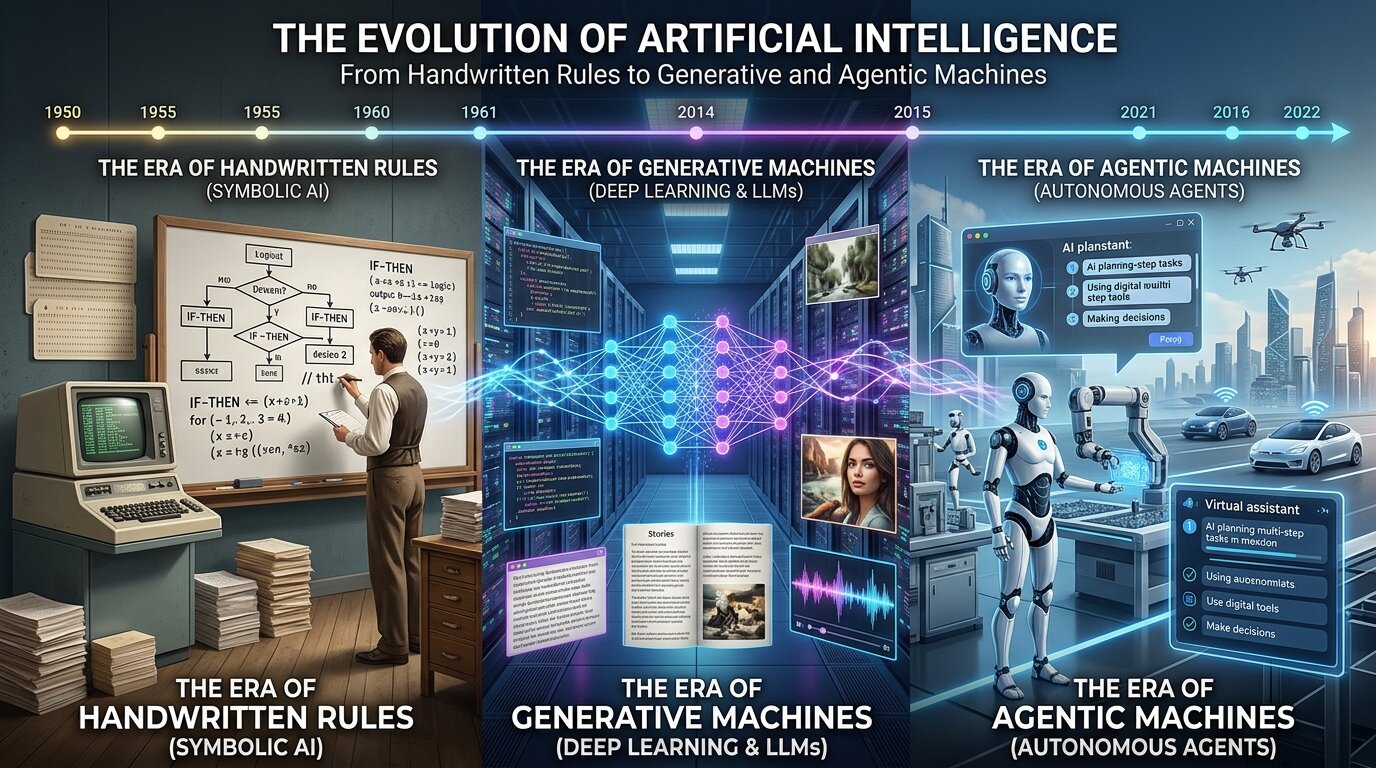
Buzzword ou non, l’IA n’est pas née avec ChatGPT. Son histoire est une succession de cycles techniques, de paris gagnés et de voies sans issue, portée autant par les algorithmes que par la puissance de calcul disponible. Des règles symboliques aux réseaux neuronaux profonds, chaque vague a empilé des idées plutôt que d’effacer la précédente. Voici comment cette trajectoire s’est bâtie… et pourquoi le matériel compte autant que les modèles.
Pourquoi l’histoire de l’IA parle aussi de matériel
Le terme “IA” est sans doute l’un des plus galvaudés de la tech. Ironique, car sa véritable histoire est bien plus riche que les slogans. L’intelligence artificielle n’est ni une invention unique ni une apparition soudaine depuis ChatGPT : c’est le produit de décennies de recherche, entre percées, impasses et remises à plat. Le champ est passé de machines censées “raisonner” par logique pure à des modèles statistiques formés sur des données, puis aux réseaux de neurones artificiels (ANN) et aux systèmes agentiques actuels.
Au fond, c’est un bras de fer permanent entre structures symboliques explicites et apprentissage de motifs statistiques. Les nouvelles époques ne remplacent pas les anciennes, elles les combinent et reviennent aux mêmes questions clés : comment représenter le monde, raisonner avec incertitude, et surtout, quelle échelle de calcul et de données pouvons-nous mobiliser ? L’IA n’a pas avancé en ligne droite : elle a évolué par vagues.
Avant que « IA » n’ait un nom
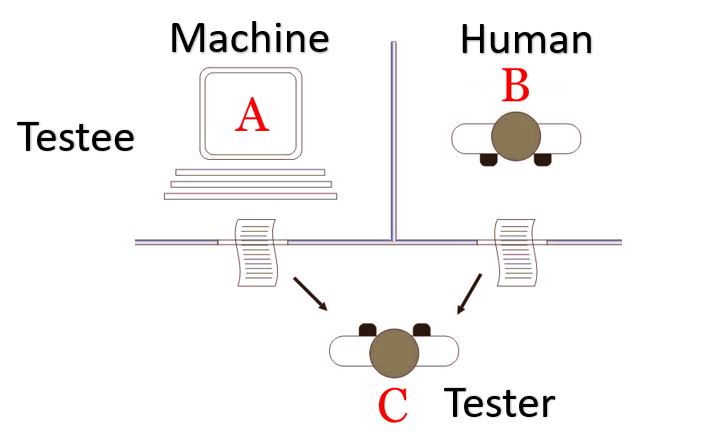
Bien avant que l’IA ne devienne une discipline, l’idée de mécaniser la pensée humaine fascinait déjà. En 1950, Alan Turing publie Computing Machinery and Intelligence et déplace la question “Une machine peut-elle penser ?” vers un test comportemental devenu le Test de Turing. Au milieu des années 1950, les chercheurs abordent l’intelligence comme un problème d’ingénierie, découpé en mémoire, recherche et décision. Le séminaire de Dartmouth marque alors la naissance officielle de l’IA académique. L’optimisme est total : certains imaginent une intelligence humaine artificielle en une génération. L’histoire dira le contraire, mais Dartmouth plante le décor : simuler l’intelligence avec des ordinateurs sera un projet scientifique sérieux.
IA classique : logique, règles et recherche
La première ère, dite IA classique ou IA symbolique, part d’une idée limpide : l’intelligence découle de règles. Si l’humain raisonne par faits et étapes, une machine peut faire pareil. On modélise alors les problèmes comme des espaces d’états à parcourir via la “recherche” et la “planification”. Dans cette vision, être intelligent revient à trouver le meilleur chemin vers l’objectif. Plusieurs méthodes fondatrices, comme l’algorithme de Dijkstra, irriguent encore l’informatique moderne, de la robotique au pathfinding des jeux vidéo.
Quand ça marche, le symbolique est élégant et transparent. Des démonstrations de théorèmes ou des jeux très structurés lui conviennent parfaitement. Mais la vraie vie est floue, ambiguë, pleine d’exceptions. Hors environnements contrôlés, ces systèmes deviennent fragiles. Une limite qui hantera longtemps le domaine.
Systèmes experts et premier boom commercial
Parmi les dérivés les plus connus du symbolique : le système expert, censé encapsuler le savoir d’un spécialiste dans une grande base de règles “si-alors”. Pendant un temps, on a cru à une transformation de la médecine et de l’entreprise en imitant le raisonnement d’experts. C’est l’un des premiers usages industriels crédibles de l’IA.

Mais la discipline se heurte vite au goulet d’étranglement de l’acquisition de connaissances : extraire et maintenir à jour des milliers de règles coûte cher et s’avère épuisant. Le décalage entre attentes et résultats déclenche alors un premier “hiver de l’IA”, quand financements et intérêt reculent.
Le tournant statistique : le machine learning change la question
Progressivement, on cesse de demander “Comment dicter à la machine ce qu’est l’intelligence ?” pour préférer “Et si la machine apprenait directement des données ?”. C’est la naissance du machine learning (ML), qui change la donne : au lieu d’écrire les règles à la main, on vise la généralisation ; on nourrit le système d’exemples et on l’optimise pour bien performer sur du neuf.
De cette période naissent des outils efficaces comme les arbres de décision, les SVM et les méthodes d’ensemble. Moins “grandioses” que des machines “pensantes”, mais très performants sur des usages concrets (détection de fraude, classement de résultats). Le ML réussit parce qu’il se montre plus humble : pas de promesse d’esprit synthétique, juste un système qui progresse à mesure qu’il voit des données.
Réseaux neuronaux : une vieille idée qui a dû attendre son heure
Paradoxalement, les réseaux neuronaux comptent parmi les idées les plus anciennes. On parle de neurones “artificiels” dès les années 1940, et le perceptron fait sensation dans les années 1950. L’ambition : laisser le système ajuster ses poids pour apprendre lui-même ses représentations.
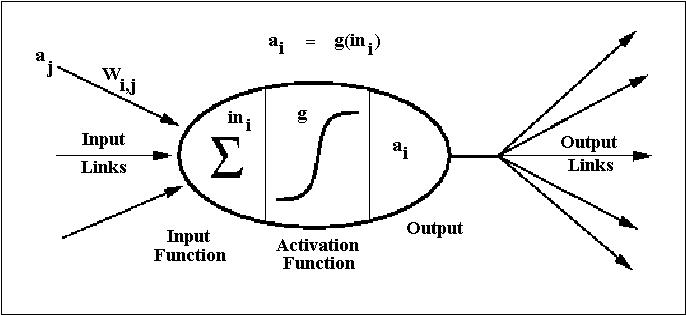
Longtemps, ces modèles butent sur le manque de calcul et de données, et l’entraînement profond reste délicat. L’arrivée de la rétropropagation et de la descente de gradient débloque enfin les architectures à plusieurs couches. Mais il faudra encore patienter : autre constante de l’IA, une bonne idée arrive souvent bien avant le matériel capable de la soutenir.
Deep learning : quand données, algorithmes et matériel s’alignent
Le deep learning n’est pas une “nouvelle espèce” d’IA ; c’est ce qui se produit quand des réseaux neuronaux, suffisamment grands et voraces en données, apprennent seuls des hiérarchies de représentations. Un modèle peu profond a besoin qu’on lui décrive un “nez” ; un modèle profond découvre d’abord des arêtes, puis des formes, puis des objets entiers.
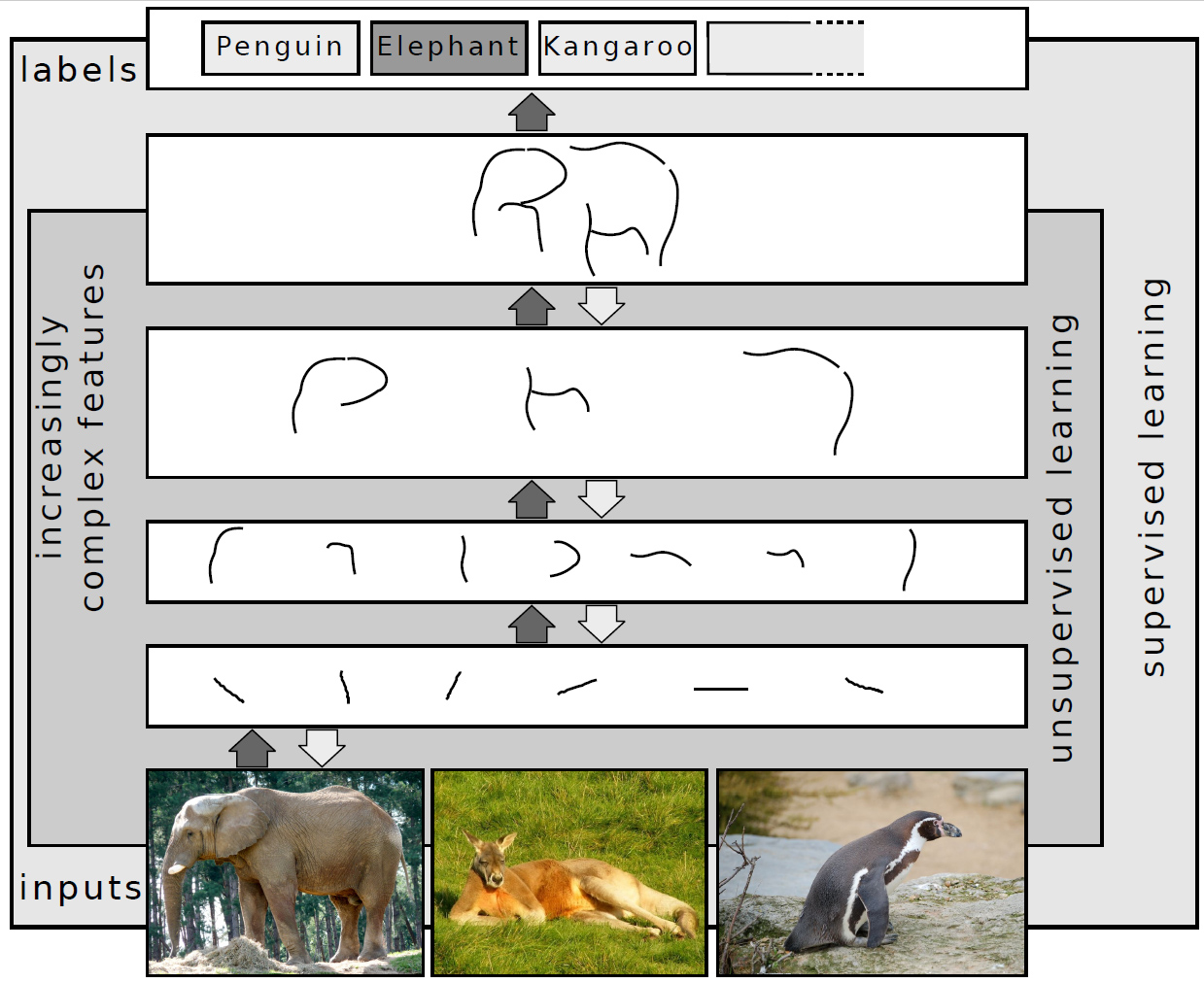
Le déclic survient en 2012 avec AlexNet, un réseau convolutionnel (CNN) qui pulvérise le benchmark ImageNet. Preuve à l’appui : avec des ensembles massifs et la puissance des Graphics Processing Units (GPUs), on débloque des problèmes restés stables des années durant, comme la vision. Point crucial : l’essor de l’IA est aussi une histoire de matériel. Pensés pour les jeux vidéo à l’origine, les GPU excellent en multiplications de matrices (“matmul”) et en algèbre linéaire, cœur des réseaux profonds (DNN). Plus tard, les Tensor Cores et des accélérateurs dédiés comme les TPU pousseront encore plus loin. Sans ces évolutions matérielles, le deep learning serait resté une curiosité académique.
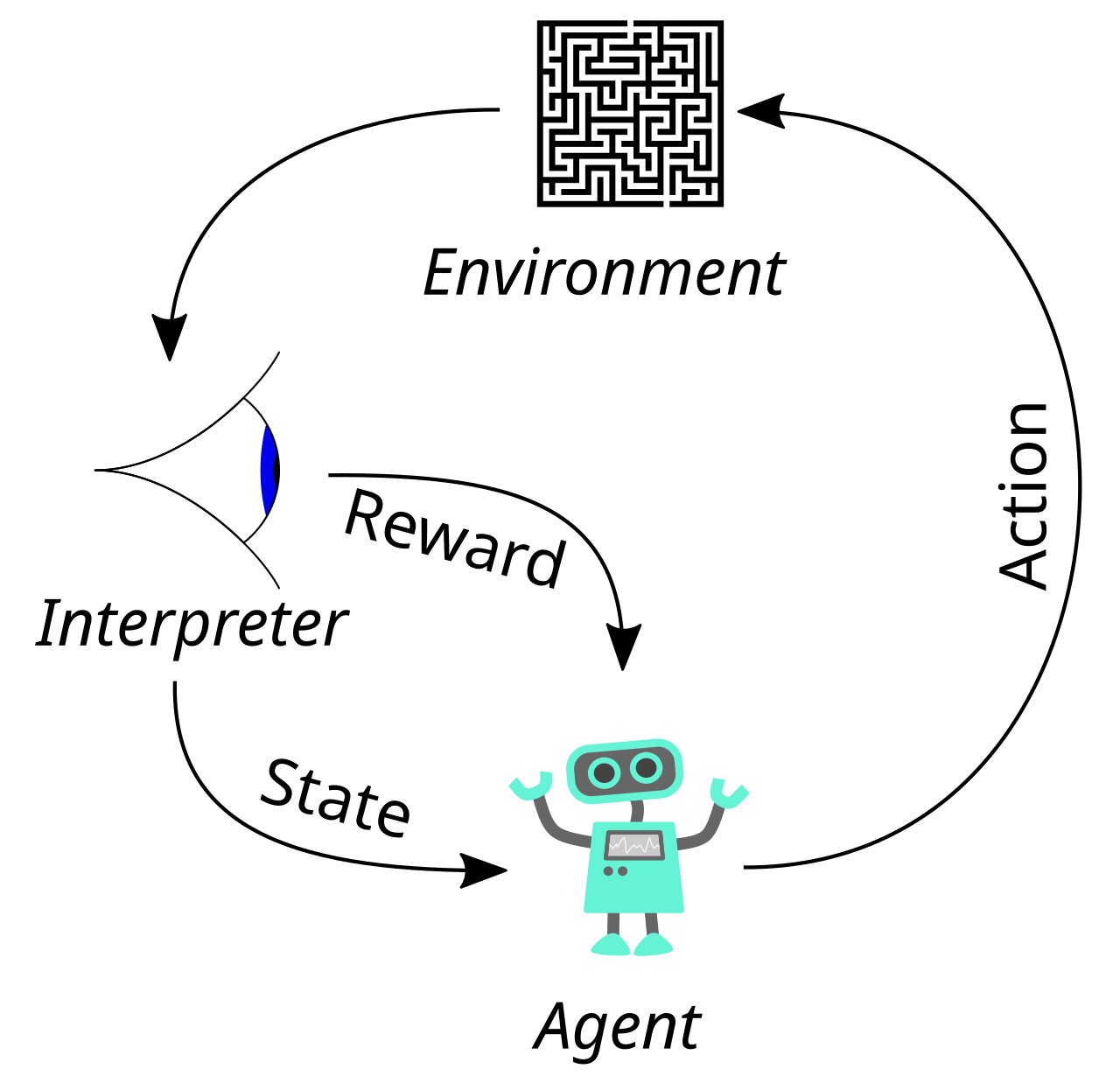
Apprentissage par renforcement : apprendre par la récompense
Tandis que la plupart des systèmes apprennent via des étiquettes, une autre branche, l’apprentissage par renforcement (RL), progresse par essai-erreur. Comme avec un chien : un agent agit, reçoit une récompense ou une pénalité, puis ajuste sa stratégie. En combinant réseaux et recherche, AlphaGo a montré que des jeux jadis jugés “inaccessibles” pouvaient être maîtrisés. La méthode symbolique n’a pas disparu : elle se marie avec l’apprentissage moderne. Aujourd’hui, le RL irrigue la robotique, le contrôle, l’optimisation et les techniques d’alignment des modèles de langage.
L’ère Transformer : l’IA cesse de penser séquentiellement
Le grand bond suivant s’appelle le Transformer. Avant, le traitement du langage naturel (NLP) s’appuyait sur des RNN qui lisaient le texte mot à mot, créant un goulet de performance. Les Transformers ont introduit l’attention, qui permet d’examiner tous les mots (ou tokens) d’une phrase en parallèle.
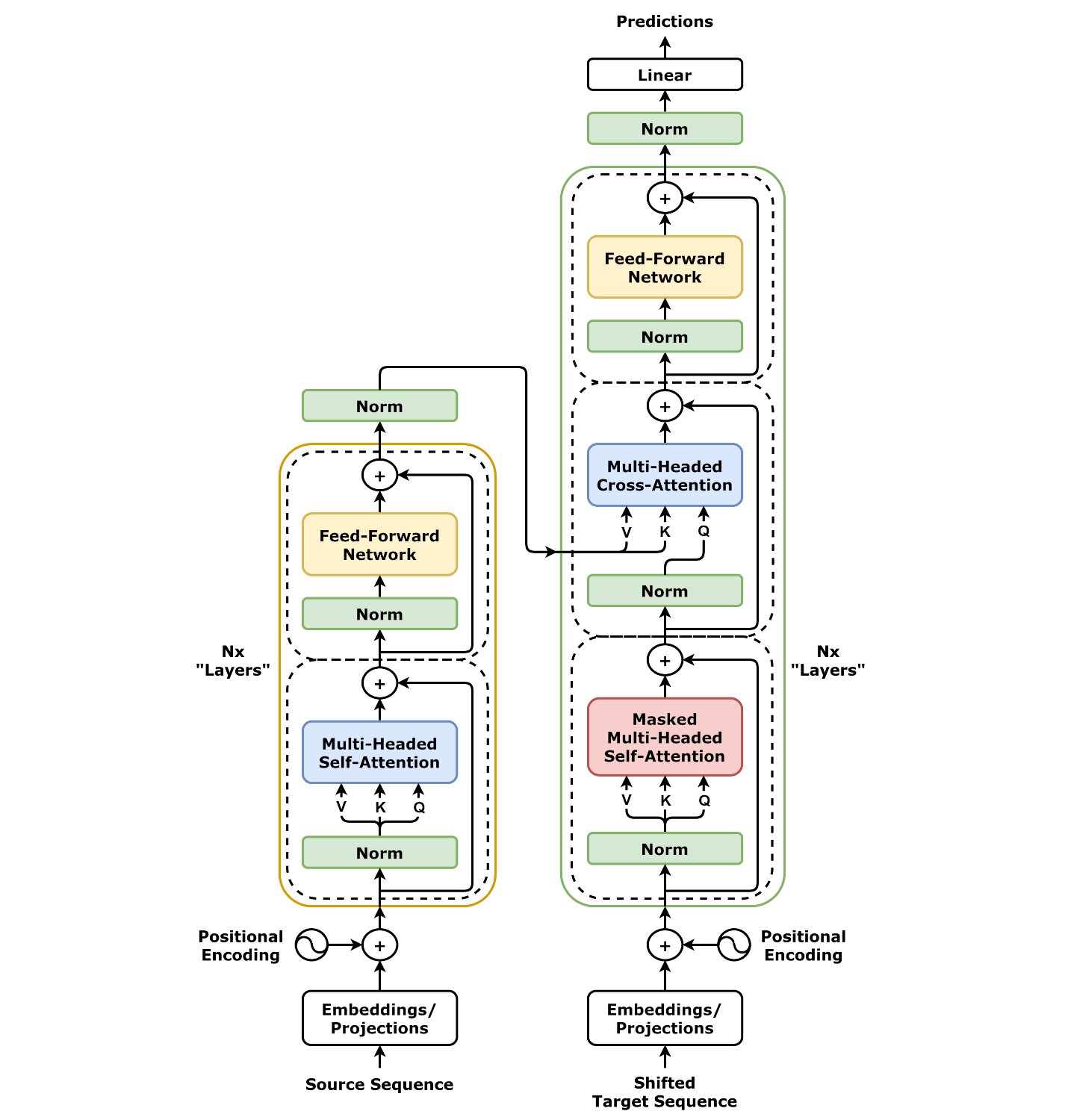
L’article de 2017 Attention Is All You Need lance la vague des grands modèles de langage (LLM). Cette architecture passe à l’échelle avec brio, parfaite pour les entraînements massifs en datacenter. La plupart des outils actuels — des LLM aux systèmes multimodaux et à la génération d’images — en découlent.
IA générative : du moteur de prédiction à la création de contenu
L’IA générative que tout le monde commente aujourd’hui est en réalité un assemblage de sous-domaines : modélisation probabiliste, modèles séquentiels neuronaux, variables latentes, apprentissage adversarial, diffusion et pré-entraînement à grande échelle. L’objectif : modéliser si bien les données qu’une machine peut produire des contenus indiscernables du réel (ou presque).

Les grands modèles de langage en sont la vitrine : en apprenant à prédire le prochain mot/token sur des corpus géants, ils résument, programment et traduisent avec une aisance déroutante. OpenAI avec GPT-3 montre qu’en changeant d’échelle, les modèles “apprennent” des capacités non spécifiquement entraînées. Côté image, les modèles de diffusion comme Stable Diffusion renversent la table en apprenant à inverser un processus de bruit. Le véritable changement, c’est l’interface : le langage naturel devient un nouveau mode de “programmation” pour le plus grand nombre.
IA agentique : l’étape d’après
Si l’IA générative sert à produire du contenu, l’IA agentique sert à accomplir des tâches.
En d’autres termes, la génération “fabrique”, l’agent “agit”. Ces systèmes ne s’arrêtent pas à un prompt : ils mobilisent mémoire, outils et boucles de planification pour résoudre des objectifs complexes. Ils découpent un but en étapes, consultent le web, révisent leur plan. Des travaux comme ReAct ont formalisé ce cycle “penser-puis-agir”.
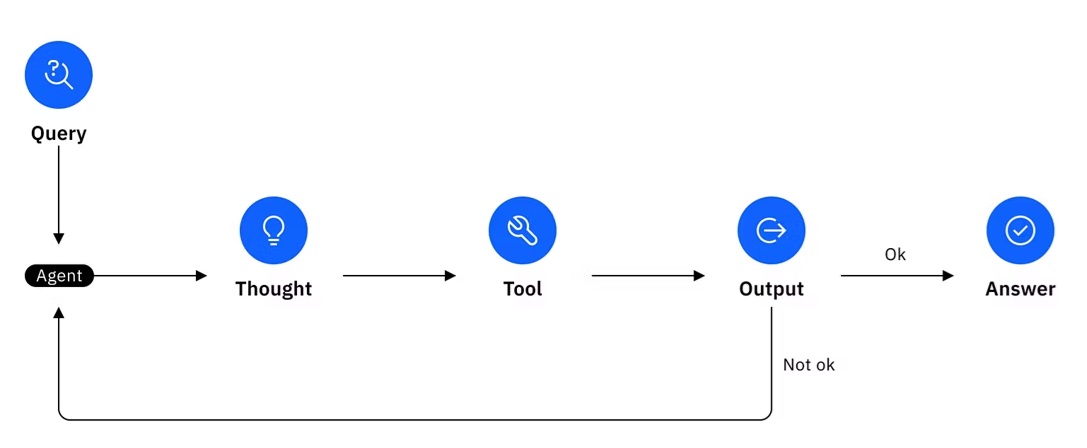
Là où ça devient intéressant : l’agentique réactive un vieux rêve du champ. L’IA symbolique parlait déjà de planification et de poursuite d’objectifs ; la différence, c’est qu’on remplace les règles rigides par de vastes LLM de centaines de milliards de paramètres comme “cerveau”. On entre dans l’ère des hybrides, où les modèles orchestrent des suites d’outils spécialisés.
Les défis qui restent à relever
Malgré les progrès, l’IA traîne encore des casseroles. Les systèmes symboliques étaient fragiles ; les modèles profonds sont souvent des boîtes noires. Les systèmes génératifs peuvent halluciner, et les agents amplifier de petites erreurs jusqu’à l’échec. D’où l’essor de cadres de sûreté comme l’AI Risk Management Framework du NIST américain et de réglementations comme l’AI Act de l’Union européenne (que la Commission européenne indique comme officiellement entré en vigueur le 1 août 2024).
Vers quoi l’IA pourrait évoluer
La suite ? Probablement pas un seul “coup de génie”, mais une convergence à grande échelle. Les systèmes deviennent plus multimodaux, outillés, persistants et intégrés dans des boucles logicielles plus vastes. Les agents ne se contenteront pas de discuter : ils opéreront sur la durée et coordonneront des workflows complexes.
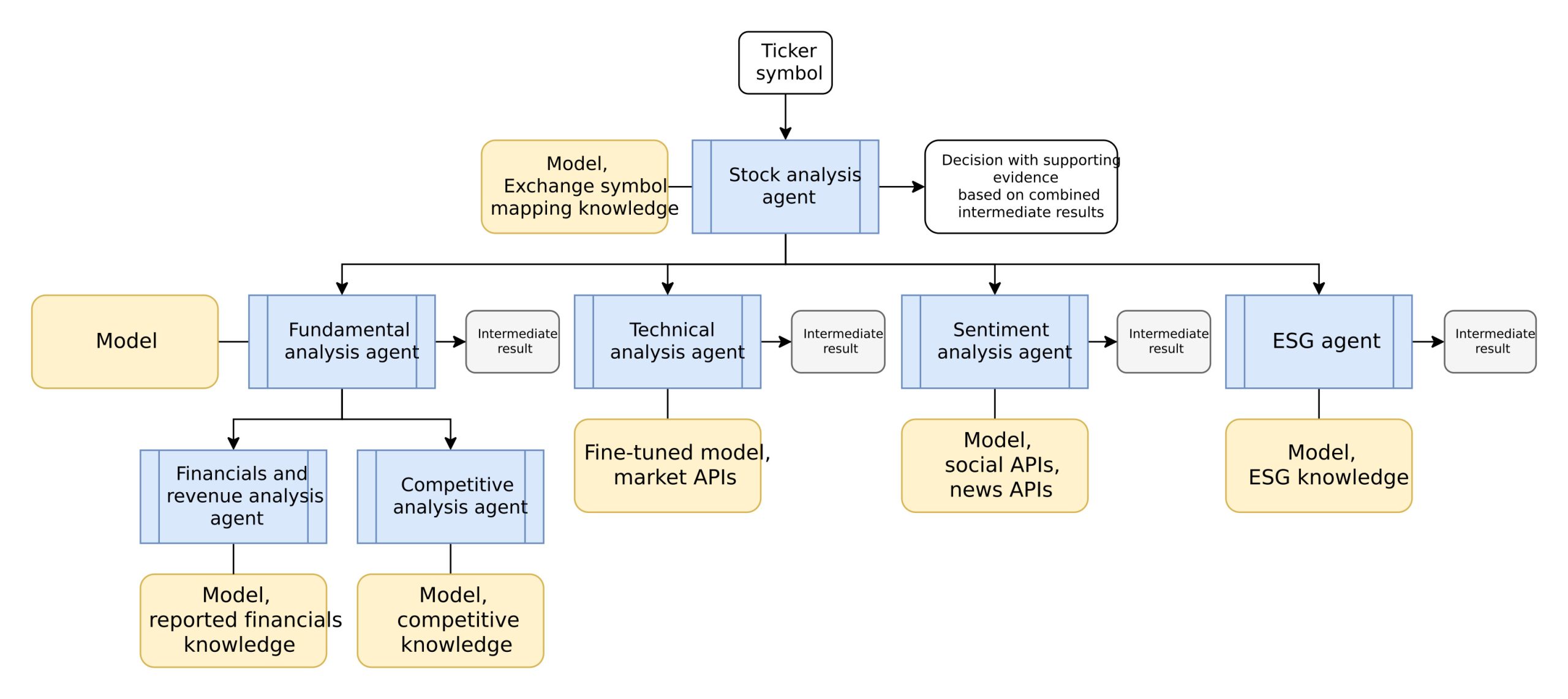
La seule montée en taille ne suffira peut-être plus : l’heure est à l’efficacité, à l’ancrage factuel et à la fiabilité. Les modèles géants nous ont amenés ici, mais de meilleurs choix d’ingénierie des systèmes feront la différence. L’avenir appartient sans doute aux hybrides qui marient la force de reconnaissance de motifs des réseaux neuronaux à la précision et à la mémoire des outils symboliques. L’ironie veut que le futur de l’IA ressemble à une réunion avec son passé.
Derniers mots
L’histoire de l’IA, c’est celle d’un champ qui redéfinit sans cesse ce qu’il entend par “intelligence”. Partie de la logique, passée par la statistique, devenue apprentissage de représentations, elle tend aujourd’hui vers des systèmes capables de générer, retrouver, raisonner et agir. Chaque vague a réglé un problème en en créant un autre. Garder cette trajectoire en tête rappelle que la période actuelle n’a rien de magique : c’est un chapitre de plus dans une longue histoire technique. La prochaine avancée naîtra moins d’une table rase que d’une recombinaison intelligente de ce que nous avons déjà appris.



