Plugin vLLM-ATOM d’AMD booste l’inférence DeepSeek-R1, Kimi-K2 et gpt-oss-120B sur Instinct MI350 et MI400

AMD présente vLLM-ATOM, un plugin dédié aux grands modèles de langage IA qui exploite pleinement les GPU Instinct MI350 et MI400. Ce module s’intègre sans heurt à vLLM pour accélérer l’inférence tout en conservant les commandes et API existantes. Les utilisateurs bénéficient ainsi des optimisations kernels d’AMD dès le lancement des nouveaux matériels.
AMD booste les LLMs IA avec son plugin vLLM-ATOM compatible vLLM et accélérant les performances d’inférence
Le plugin vLLM-ATOM optimise les performances d’inférence pour divers grands modèles de langage IA. Il cible les accélérateurs GPU Instinct haut de gamme d’AMD, comme les séries MI350 et MI400, en mode serveur autonome ou intégré comme backend plugin. Les utilisateurs profitent des optimisations natives de modèles et kernels AMD sans toucher à la base de vLLM.
Les principaux atouts de vLLM-ATOM sont :
- Zéro courbe d’apprentissage : Compatibilité totale avec les commandes, API et flux de travail vLLM actuels. ATOM fonctionne en arrière-plan de façon transparente, sans outils supplémentaires ni configurations complexes, tout en améliorant les performances kernels pour une expérience utilisateur inchangée.
- Accès direct aux innovations AMD : Exploitation immédiate des fonctionnalités hardware avancées (comme FP4 sur le GPU MI355X ou inférence à l’échelle rack sur MI400) et optimisations kernels supérieures (AITER fused attention, AllReduce personnalisé), sans attendre leur intégration dans le code principal de vLLM. Cela accélère le déploiement des nouveaux GPU AMD.
- Sandbox agile pour innovations : Espace de validation rapide pour idées techniques, activation hardware et tests de bibliothèques kernels (comme AITER). Le plugin s’aligne sur la roadmap AMD, couvrant sorties GPU, support FP8/FP4 et mécanismes d’attention futurs, indépendamment des cycles de sortie vLLM.
- vLLM comme base solide pour ROCm : Framework standard communautaire, vLLM offre stabilité entreprise, couverture étendue de modèles et fonctions critiques pour déployer à grande échelle l’infrastructure ROCm.
- Optimisations matures intégrées pour tous : ATOM teste temporairement les nouveautés ; une fois validées, les kernels, stratégies et fonctions rejoignent le backend ROCm natif de vLLM, profitant à l’ensemble de la communauté ROCm et open-source LLMs.
L’architecture vLLM-ATOM se divise en trois couches :
| Couche | Rôle |
|---|---|
| vLLM | Ordonnancement des requêtes, gestion KV cache, batching continu, API compatible OpenAI |
| ATOM Plugin | Enregistrement plateforme, implémentation modèles optimisée, routage backends attention, réglage optimisations kernels |
| AITER | Kernels GPU bas niveau : MoE fusionné, flash attention, GEMM quantifié, fusion RoPE |
Pour le support modèles, vLLM-ATOM gère LLMs et VLMs via un pipeline unifié. Voici la liste complète :
| Architecture | Type | Modèles représentatifs | Classe modèle ATOM |
|---|---|---|---|
| Qwen3MoeForCausalLM | MoE | Qwen/Qwen3-235B-A22B-Instruct-2507-FP8 | atom.models.qwen3_moe |
| DeepseekV3ForCausalLM | MoE (MLA) | deepseek-ai/DeepSeek-R1-0528 (FP8), amd/DeepSeek-R1-0528-MXFP4, amd/Kimi-K2-Thinking-MXFP4 | atom.models.deepseek_v2 |
| GptOssForCausalLM | MoE | openai/gpt-oss-120b | atom.models.gpt_oss |
| Glm4MoeForCausalLM | MoE (MLA) | zai-org/GLM-4.7-FP8 | atom.models.glm4_moe |
| Qwen3NextForCausalLM | Hybrid MoE | Qwen/Qwen3-Next-80B-A3B-Instruct-FP8 | atom.models.qwen3_next |
| Qwen3_5ForConditionalGeneration | Dense (Text/VLM) | Qwen/Qwen3.5-35B-A3B-FP8 | atom.models.qwen3_5 |
| Qwen3_5MoeForConditionalGeneration | MoE (Text/VLM) | Qwen/Qwen3.5-397B-A17B-FP8 | atom.models.qwen3_5 |
| KimiK25ForConditionalGeneration | MoE (Text/VLM) | amd/Kimi-K2.5-MXFP4 | atom.models.kimi_k25 |
Note d’AMD : vLLM-ATOM montre que optimisations hardware spécifiques et compatibilité framework coexistent. Grâce au mécanisme plugin natif de vLLM, ATOM fournit kernels AMD natifs (attention fusionnée, GEMM quantifié, routage MoE optimisé) tout en gardant l’ensemble des fonctions vLLM essentielles aux déploiements production.
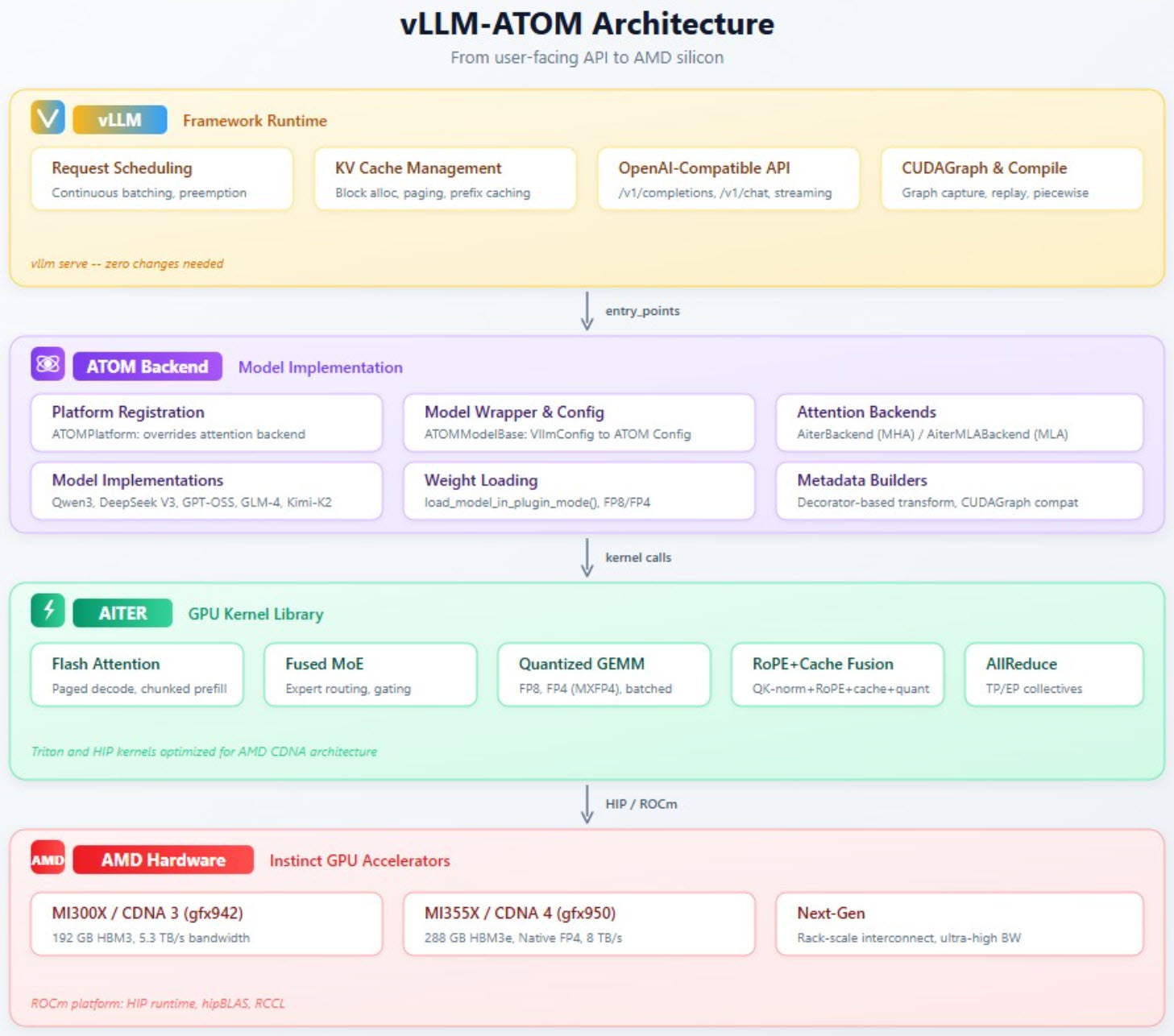
Au-delà des gains immédiats, l’architecture du plugin valide les innovations hardware et software AMD : les optimisations testées en mode plugin rejoignent progressivement le backend ROCm natif de vLLM, profitant à toute la communauté ROCm et open-source LLMs. Les utilisateurs accèdent sans délai aux capacités des derniers GPU AMD, favorisant une évolution mutuelle entre hardware AMD et écosystème vLLM.
- Documentation ATOM
- Guide vLLM-ATOM
- RFC : Activation ATOM comme plateforme vLLM hors arbre
- Répertoire ATOM
- AITER – Moteur tenseur inférence AMD pour ROCm
- Recettes vLLM-ATOM
- Docker Hub – Images ATOM + vLLM



