NVIDIA lance un LLM open-source de 72 milliards de paramètres

NVIDIA a récemment lancé un modèle de langage open-source, NVLM 1.0, qui rivalise avec les meilleures solutions du secteur, telles qu’OpenAI et Google. Ce modèle multimodal promet des performances impressionnantes en offrant à la fois des réponses textuelles améliorées et des capacités avancées en mathématiques et raisonnement, ouvrant la voie à de nouvelles innovations.

NVIDIA, qui produit certaines des GPU les plus prisées dans le secteur de l’IA, a annoncé avoir lancé un modèle de langage open-source qui rivalise en performance avec les modèles propriétaires d’OpenAI, Anthropic, Meta et Google.
L’entreprise a présenté sa nouvelle famille NVLM 1.0 dans un document blanc récemment publié, menée par le modèle NVLM-D-72B, qui comprend 72 milliards de paramètres. « Nous introduisons NVLM 1.0, une famille de modèles de langage multimodaux de classe avant-garde qui obtiennent des résultats à la pointe dans les tâches de vision et de langage, rivalisant avec les meilleurs modèles propriétaires (par exemple, GPT-4o) et les modèles en accès libre », ont écrit les chercheurs.
Introducing NVLM 1.0, a family of frontier-class multimodal LLMs that achieve state-of-the-art results on vision-language tasks, rivaling the leading proprietary models (e.g., GPT-4o) and open-access models (e.g., InternVL 2).
Remarkably, NVLM 1.0 shows improved text-only… pic.twitter.com/yKGyOqHnsp— Wei Ping (@_weiping) Septembre 18, 2024
Cette nouvelle famille de modèles semble déjà capable de « multimodalité de grade production », montrant des performances exceptionnelles sur une variété de tâches de vision et de langage, en plus d’offrir des réponses textuelles améliorées par rapport au modèle de base sur lequel repose la famille NVLM. « Pour y parvenir, ils ont conçu et intégré un ensemble de données textuelles de haute qualité au sein d’un entraînement multimodal, en plus d’une quantité substantielle de données mathématiques et de raisonnement multimodales, entraînant une amélioration des capacités en mathématiques et en code à travers les modalités », ont expliqué les chercheurs.
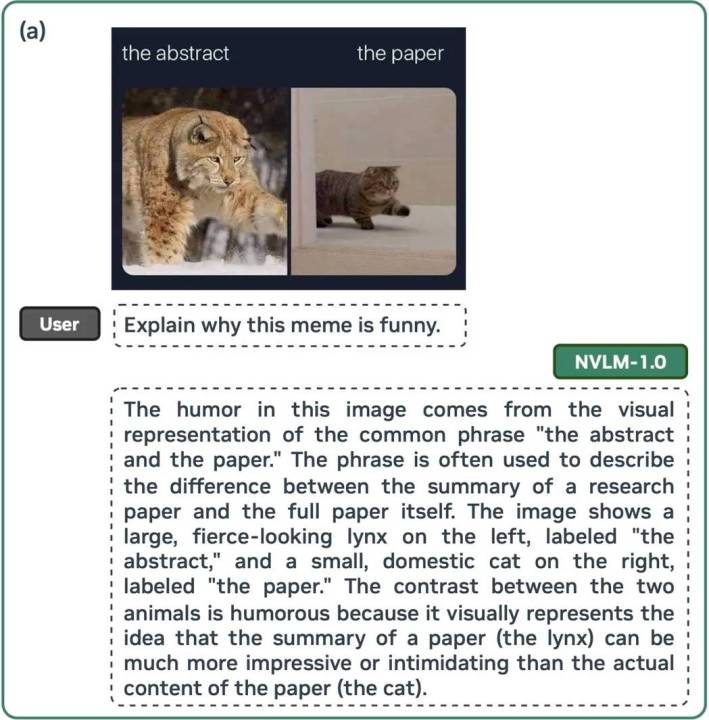
Le résultat est un modèle de langage qui peut tout aussi facilement expliquer pourquoi un mème est drôle que résoudre des équations mathématiques complexes, étape par étape. NVIDIA a également réussi à augmenter l’exactitude des réponses textuelles du modèle de 4,3 points en moyenne sur des benchmarks industriels communs, grâce à son style d’entraînement multimodal.
NVIDIA semble déterminée à respecter la nouvelle définition « open source » de l’Open Source Initiative en rendant non seulement ses poids d’entraînement disponibles pour test public, mais également en promettant de publier le code source du modèle dans un avenir proche. Cela marque un départ notable par rapport aux actions de concurrents comme OpenAI et Google, qui protègent jalousement les détails des poids et du code source de leurs modèles de langage. Ce faisant, NVIDIA a positionné la famille NVLM non pas uniquement en concurrence directe avec ChatGPT-4o et Gemini 1.5 Pro, mais en tant que fondation pour que des développeurs tiers puissent créer leurs propres chatbots et applications IA.



