Alibaba vise Hopper de NVIDIA avec son GPU Zhenwu M890, affirme 3 fois la performance du H20, 144GB HBM3 et une roadmap jusqu’en 2028

Alibaba Cloud dévoile simultanément sa dernière génération de puces d’accélération IA et un nouveau modèle de langage de taille conséquente. Le Zhenwu M890 et le Qwen3.7-Max visent à constituer une plateforme complète pour les tâches d’IA dites agentiques, une réponse directe aux acteurs dominants du secteur.
Le Zhenwu M890 : La nouvelle puce IA maison d’Alibaba
Alibaba présente son dernier GPU dédié à l’intelligence artificielle, le Zhenwu M890. Cette nouvelle puce repose sur une architecture PPU (Parallel Processing Unit) conçue en interne, intégrant de manière native un moteur de coeur Transformer. Elle est pensé spécifiquement pour l’inférence dans les charges de travail d’IA agentique.
Alibaba revendique une puissance de calcul de 0,6 PFLOPs en FP16, une performance comparable au A100 de NVIDIA et jusqu’à trois fois supérieure aux solutions H20 de la gamme Hopper. La société affirme également que ses performances sont triplées par rapport à sa génération précédente.

Coté spécifications, le Zhenwu M890 est équipé de 144 Go de mémoire HBM3, soit une augmentation de 50% par rapport au Zhenwu 810E qui disposait de 96 Go. La bande passante d’interconnexion passe à 800 Go/s, gagnant 100 Go/s. La nouvelle puce supporte les formats FP32, FP16, FP8 et FP4 pour les charges de travail IA, la positionnant à un niveau similaire aux capacités des gammes Rubin de NVIDIA et Ascend 950 de Huawei.

La société propose un écosystème complet avec l’introduction d’une nouvelle puce d’interconnexion, l’ICN Switch 1.0. Ce composant offre des débits de 25,6 Tb/s avec une latence point à point inférieure à 150 ns. Cette bande passante élevée permet de supporter une concurrence d’agents massivement parallèles. L’ensemble inclut également le CPU hôte basé sur Arm Yitian et les cartes réseau de la série Panmai, le tout étant intégré au sein du serveur Panjiu AL128 Supernode par Alibaba Cloud.

Ce nouveau serveur intégrera 128 accélérateurs d’IA dans un seul rack, offrant une bande passante à l’échelle du pétaoctet par seconde. T-Head rapporte avoir expédié environ 560 000 puces Zhenwu IA à ce jour, pour plus de 400 clients externes répartis dans 20 industries.
| Date de sortie | Modèle | Points forts | Évolution des capacités |
|---|---|---|---|
| 2024 T2 | Zhenwu 810E | Puce IA tout-en-un facile à utiliser pour l’entraînement et l’inférence ; 96 Go de mémoire ; bande passante d’interconnexion de 700 Go/s | Base de référence (première génération) |
| 2026 T2 | Zhenwu M890 | Architecture de calcul parallèle développée en interne entièrement mise à jour ; performances x3 ; 144 Go de mémoire ; bande passante d’interconnexion de 800 Go/s | Performances globales boostées d’environ x3 ; mémoire de 96 Go à 144 Go (+50%) ; bande passante de 700 à 800 Go/s (+14%) ; architecture entièrement mise à jour |
| 2027 T3 | Zhenwu V900 | Itération approfondie de l’architecture de calcul parallèle interne ; performances x3 ; 216 Go de mémoire ; bande passante d’interconnexion de 1200 Go/s | Performances boostées de nouveau x3 ; mémoire de 144 Go à 216 Go (+50%) ; bande passante de 800 à 1200 Go/s (+50%) ; architecture profondément itérée |
| 2028 T3 | Zhenwu J900 | Innovation de rupture dans l’architecture de calcul parallèle interne ; saut de performance continu attendu | L’architecture atteint une innovation de rupture ; les performances devraient continuer à faire un bond majeur, visant le niveau des meilleures puces IA internationales |
Alibaba Cloud travaille déjà sur une série de puces Zhenwu succédant au M890.

L’année prochaine au troisième trimestre, la société prévoit d’introduire le V900, avec une architecture mise à jour offrant un gain de performances de 3x, 216 Go de mémoire et 1200 Go/s de bande passante. Son successeur, le Zhenwu J900, arrivera au T3 2028 avec des améliorations architecturales et de performances encore plus poussées.
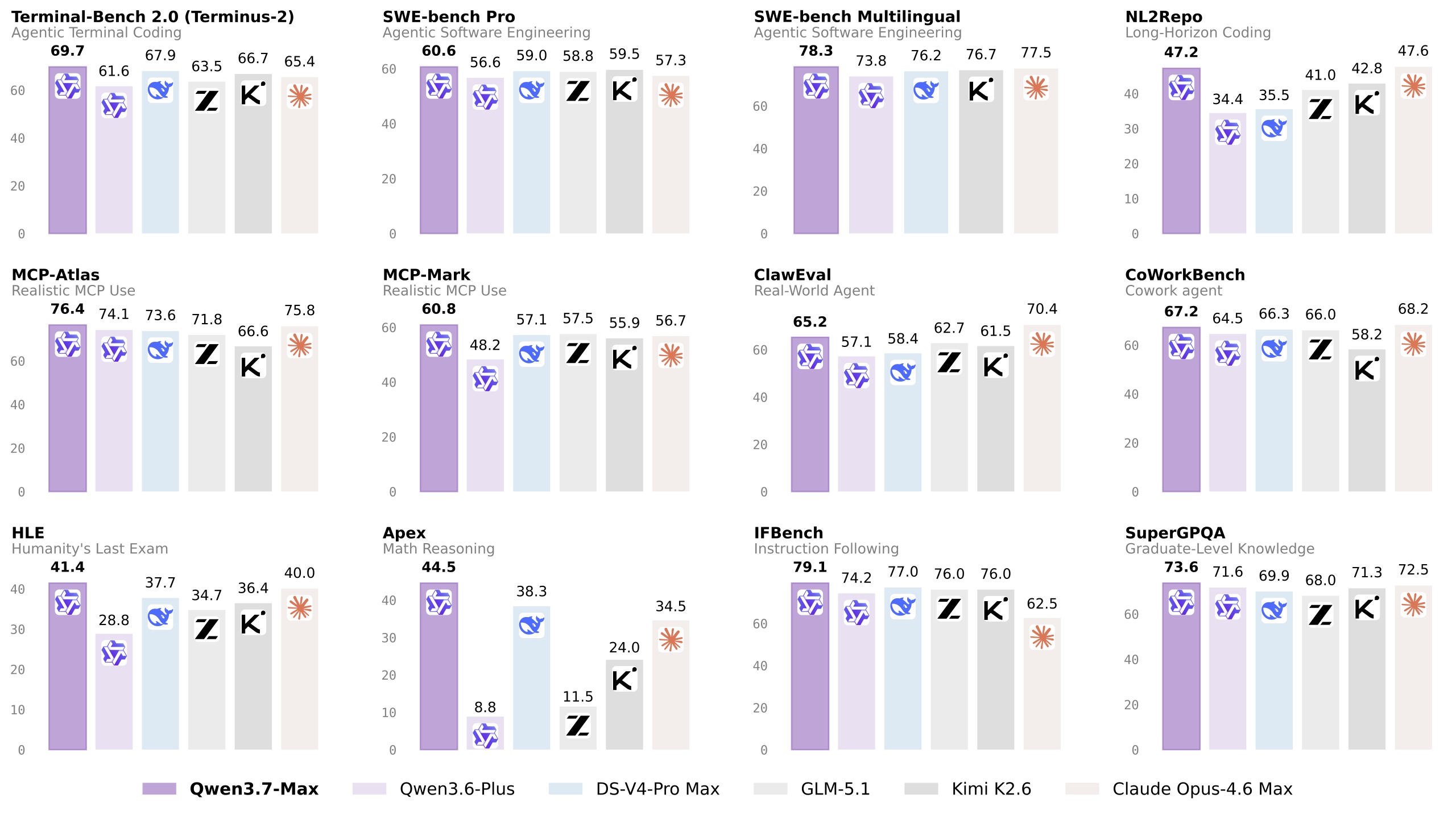

Le modèle offre des capacités d’agent exceptionnelles dans divers domaines. En tant qu’assistant de codage de pointe, il prend en charge des tâches allant du prototypage frontal rapide à l’ingénierie logicielle complexe et multi-fichiers. Pour améliorer la productivité du travail de bureau, il orchestre de manière fiable des workflows multi-agents pour gérer des opérations sophistiquées. Il est à noter que Qwen 3.7-Max peut exécuter de manière autonome des tâches agentiques de long horizon, en maintenant une opération continue jusqu’à 35 heures et en gérant plus de 1 000 appels d’outils sans dégradation des performances.
Profondément optimisé pour les principaux frameworks d’agents, dont OpenClaw, Hermes Agent, Claude Code, Qwen Paw et Qoder, il sert de fondation fiable pour différents systèmes d’agents. Le modèle atteint des résultats de premier ordre sur les principaux benchmarks en codage, agents à usage général, capacités générales et multilinguisme, le rendant compétitif avec les principaux modèles de pointe. Il sera bientôt accessible via la plateforme de services de modèles Model Studio d’Alibaba pour les développeurs du monde entier.
Alibaba Cloud
| Travail | Opus-4.6 Max | K2.6 Thinking | GLM-5.1 Thinking | DS-V4-Pro Max | Qwen3.6-Plus | Qwen3.7-Max |
|---|---|---|---|---|---|---|
| Agent de Codage | ||||||
| Terminal Bench 2.0-Terminus | 65,4 | 66,7 | 63,5 | 67,9 | 61,6 | 69,7 |
| SWE-Verified | 80,8 | 80,2 | — | 80,6 | 78,8 | 80,4 |
| SWE-Pro | 57,3 | 59,5 | 58,8 | 59,0 | 56,6 | 60,6 |
| SWE-Multilingual | 77,5 | 76,7 | — | 76,2 | 73,8 | 78,3 |
| NL2repo | 47,6 | 42,8 | 41,0 | 35,5 | 34,4 | 47,2 |
| SciCode | 51,9 | 52,2 | 45,1 | — | 41,4 | 53,5 |
| QwenWebDev | 1617 | — | 1564 | 1570 | 1500 | 1568 |
| QwenSVG | 1541 | 1325 | 1605 | 1506 | 1432 | 1608 |
| Agent Général | ||||||
Parallèlement à ses puces, Alibaba Cloud lance aussi son dernier modèle de langage, le Qwen3.7-Max. Ce modèle se concentre sur le codage agentique avancé, le raisonnement complexe et l’exécution de tâches de longue durée. Il sera bientôt accessible aux développeurs et aux entreprises.



