Un projet open source progresse pour amener CUDA sur les GPU non-NVIDIA

Un projet open-source travaille à permettre l’exécution d’applications CUDA sur des GPU tiers, élargissant ainsi les choix matériels et rendant le calcul GPU plus accessible. L’équipe de Zluda progresse rapidement, avec des développeurs dédiés, et améliore la compatibilité et l’exécution des applications CUDA sur diverses architectures.
NVIDIA a lancé CUDA en 2006 en tant qu’API propriétaire, un élément central pour exploiter la puissance de calcul parallèle des GPU. CUDA est essentiel dans des domaines tels que l’intelligence artificielle, le calcul scientifique et les simulations haute-performance. Cependant, l’exécution de code CUDA était principalement restreinte au hardware NVIDIA. Un projet open-source cherche à lever cette restriction.
En permettant l’exploitation d’applications CUDA sur des GPU tiers provenant d’AMD, Intel et d’autres, cette initiative pourrait élargir considérablement le choix hardware, limiter la dépendance envers un seul fournisseur et rendre le calcul GPU puissant plus accessible que jamais.
L’équipe de Zluda a récemment partagé sa dernière mise à jour trimestrielle, confirmant que le projet reste concentré sur l’implémentation complète de la compatibilité CUDA sur des accélérateurs graphiques non-NVIDIA. L’objectif déclaré de Zluda est d’offrir un remplacement direct de CUDA sur les architectures GPU d’AMD, Intel et d’autres, permettant aux utilisateurs et aux développeurs d’exécuter des applications basées sur CUDA sans modification, avec des performances « proches du natif ».
Un changement prometteur pour Zluda est que son équipe a doublé de taille. Deux développeurs à temps plein travaillent désormais sur le projet. Le nouveau développeur, connu sous le nom de « Violet », a déjà apporté des contributions significatives au dépôt officiel open-source de l’outil sur GitHub.
Parmi les autres mises à jour importantes, on trouve des améliorations du runtime GPU ROCm/HIP, qui devrait désormais fonctionner de manière fiable tant sous Linux que sous Windows. Les runtimes GPU comme CUDA et ROCm sont conçus pour compiler le code GPU à l’exécution, s’assurant que le code développé pour du hardware plus ancien peut généralement être compilé et exécuté sur des architectures GPU plus récentes avec peu de problèmes.
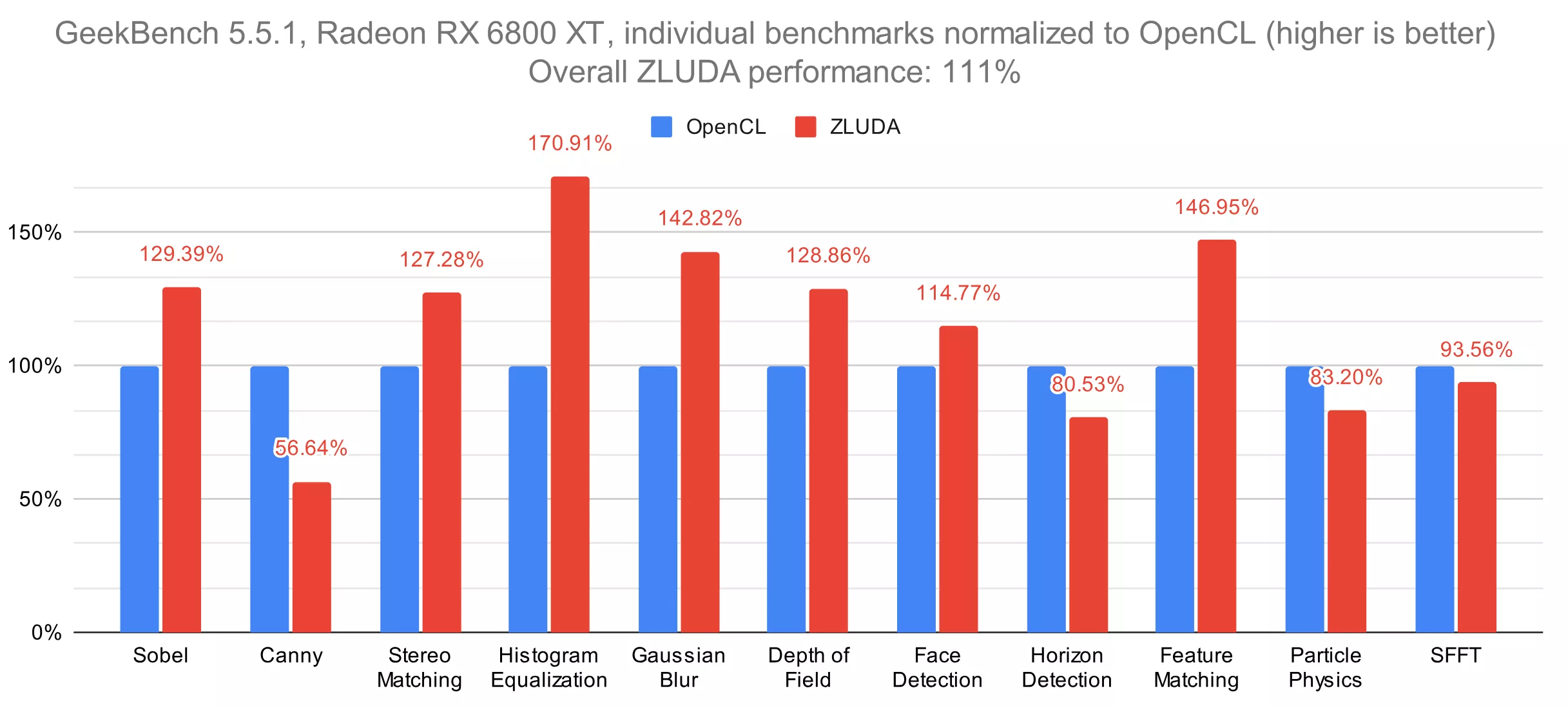
Zluda est désormais considérablement plus efficace pour exécuter des binaires CUDA non-modifiés sur des GPU non-NVIDIA. Auparavant, l’outil ignorait certains modificateurs d’instructions ou échouait à les exécuter avec une précision complète. Désormais, le code amélioré peut gérer certains des cas les plus complexes – comme l’instruction cvt – avec une précision binaire.
Une étape clé pour le support complet des applications CUDA consiste à suivre comment le code interagit avec l’API grâce à une journalisation détaillée. Zluda a également progressé dans ce domaine. Il peut désormais capturer des interactions précédemment négligées et même gérer des appels API intermédiaires.
Les développeurs ont également réalisé des progrès significatifs en prenant en charge llm.c, une mise en œuvre de test purement CUDA (écrite en C) pour des modèles de langage tels que GPT-2 et GPT-3. Zluda implémente actuellement 16 des 44 fonctions dans llm.c, et l’équipe espère exécuter complètement le test prochainement.
Enfin, Zluda a avancé légèrement dans son potentiel support pour le code PhysX 32 bits. NVIDIA a abandonné à la fois le support hardware et logiciel pour ce middleware avec les GPU GeForce 50 basés sur Blackwell, laissant les fans de vieux (mais pas trop) jeux avec une expérience qualifiable de brisée ou médiocre.
Au cours du dernier trimestre, Zluda a reçu une mise à jour mineure concernant le support PhysX 32 bits. L’accent initial est mis sur la collecte efficace des journaux CUDA pour identifier d’éventuels bugs, ce qui peut finalement affecter le code PhysX 64 bits. Cependant, les développeurs préviennent que le support complet de PhysX 32 bits nécessite probablement d’importantes contributions de développeurs tiers.



