Système AI Catalina Pod de Meta : NVIDIA Blackwell GB200 NVL72, Open Rack v3 et refroidissement liquide

Meta a récemment dévoilé les éléments clés de son système d’IA Catalina, s’appuyant sur la solution GPU NVL72 d’NVIDIA, avec Open Rack v3 et un système de refroidissement liquide.
En 2022, Meta a principalement géré des clusters comptant près de 6,000 GPU, conçus pour des modèles de classement et de recommandation. Ces systèmes traitaient des charges de travail s’étalant sur 128 à 512 GPU.
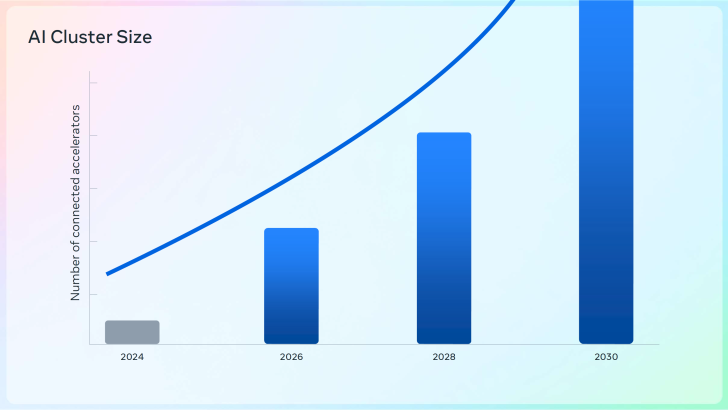
Un an après, l’émergence de la GenAI et des LLMs a fait exploser les tailles de cluster à 16-24K GPU, marquant une augmentation de quatre fois. Actuellement, Meta fait fonctionner 100,000 GPU et prévoit d’en ajouter encore, anticipant une multiplication par dix des tailles de clusters dans un futur proche.

Meta affirme avoir débuté le projet Catalina très tôt avec NVIDIA, intégrant leur solution de GPU NVL72 comme base. Les deux partenaires ont également contribué à la conception de référence pour MGX et NVL72 en open source, et Catalina est désormais en ligne sur le site Open Compute.

Diving into les aspects déployés par Meta, chaque système est désigné comme un pod, qu’ils utilisent en plusieurs exemplaires pour l’évolutivité.
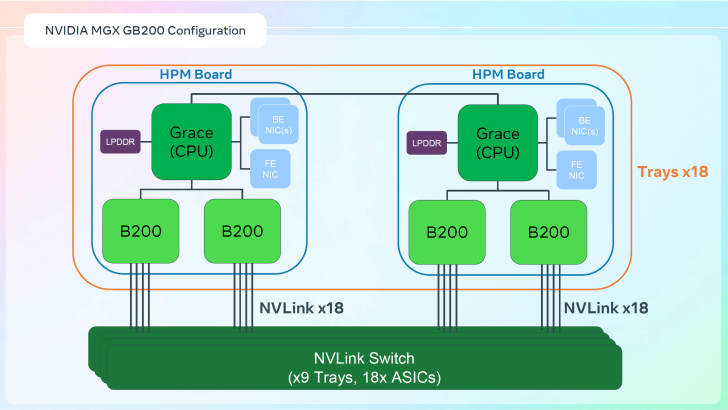
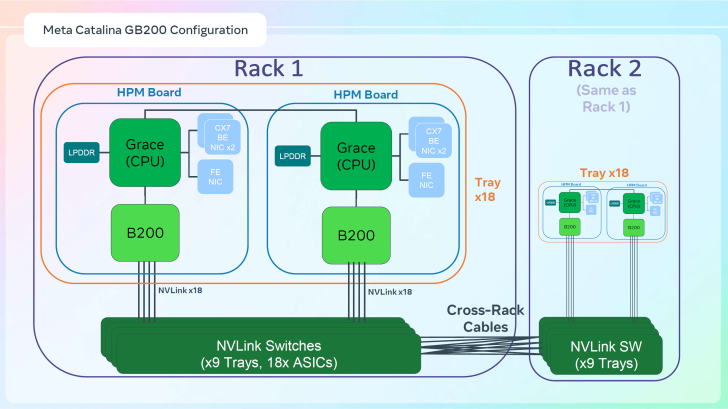
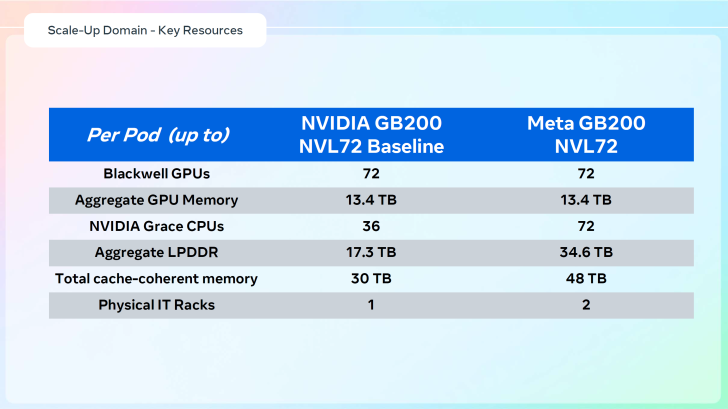
Une particularité entre la version standard de la NVL72 et celle personnalisée par Meta repose sur deux racks IT. Ces racks constituent un domaine d’échelle unique de 72 GPU. Chaque rack dispose de 18 plateaux de calcul, répartis entre le haut et le bas.
Cela permet de combiner les GPU sur les deux racks, connectés via des commutateurs NV, pour créer un domaine d’échelle unique de 72 GPU. Des dispositifs de refroidissement liquide assisté par air (ALC) sont également présents, optimisant la densité énergétique.

Avec cette configuration, Meta réussit à accroître le nombre de CPU et la mémoire totale par rack, atteignant jusqu’à 48 To de mémoire cache-cohérente. Source d’alimentation convertit 480 ou 277 volts monophasés en 48 volts DC, alimentant les lames de serveur et dispositifs de réseau.
Les racks présentent un étagère d’alimentation en haut et deux en bas. Meta utilise également un panneau de chemin de fibre pour gérer le cablage réseau en arrière-plan, reliant aux commutateurs de réseau finaux.
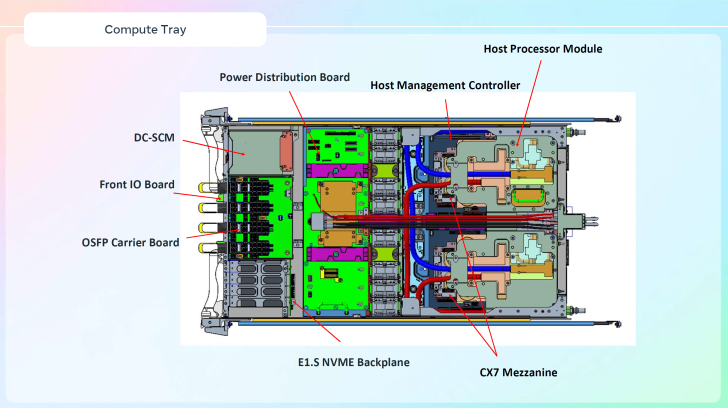
Pour soutenir tout cela, Meta adopte plusieurs technologies intégrées au système NVL72 GB200. Parmi celles-ci, une version à haute puissance de leurs racks ouverts, spécifique à Meta, et un système de refroidissement liquide adapté aux racks traditionnels. Le contrôleur de gestion de rack (RMC) agit comme un dispositif de sécurité, surveillant également les fuites.
Cette première mise en service de Meta de la version haut de gamme de son rack OpenRack v3 augmente la puissance à 94 kW par rack. Cela répond également aux normes des nouveaux bâtiments, intégrant le refroidissement liquide directement dans les racks via le RMC.
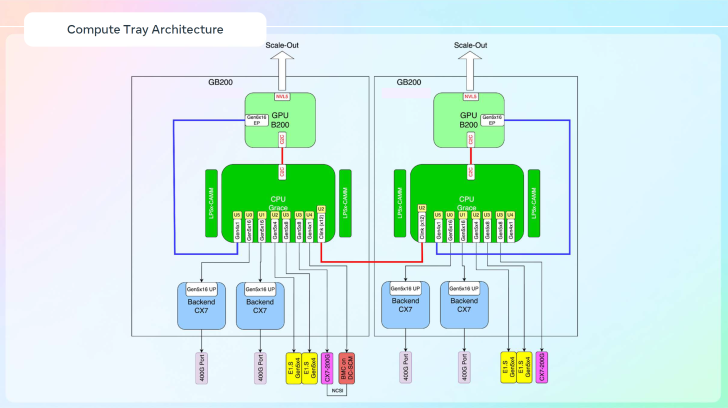
Meta exploite également sa propre architecture de réseau désagrégé pour le projet Catalina, permettant de relier plusieurs pods et bâtiments. Cela vise à créer des clusters de grande envergure, optimisés pour l’IA, offrant flexibilité et rapidité dans la communication entre GPU.



