NVIDIA Blackwell Ultra “GB300” GPU : le processeur IA le plus rapide avec 20K cœurs et 288 Go HBM3e

NVIDIA a récemment présenté son nouveau processeur pour l’IA, le Blackwell Ultra GB300, qui affiche une performance 50 % supérieure à celle du GB200 et embarque 288 Go de mémoire.
NVIDIA Blackwell Ultra « GB300 » : Un Processeur AI Performant
Il y a quelques jours, NVIDIA a dévoilé un article site de ventes son dernier processeur pour l’IA, le GB300 Blackwell Ultra. Ce composant est désormais en production et a déjà été livré à des clients clés. Bien qu’il s’agisse d’une extension de la solution Blackwell, il apporte des améliorations significatives.

Tout comme la série Super de NVIDIA améliore les cartes de jeu RTX, la série Ultra est une version améliorée des processeurs IA déjà présents. Les gammes précédentes comme Hopper et Volta n’avaient pas d’offres Ultra, mais techniquement elles en avaient des versions optimisées. Bien que les puces Ultra soient meilleures sur le plan hardware, des mises à jour logicielles offrent également des gains significatifs.

Le Blackwell Ultra GB300 repose sur deux dies de taille Reticule, connectés via l’interface NV-HBI d’NVIDIA, simulant un seul GPU. Ce processeur est dense et repose sur le nœud TSMC 4NP, intégrant 208 milliards de transistors. L’interface NV-HBI assure un débit de 10 To/s pour les deux dies de GPU, tout en fonctionnant comme un seul composant.

Avec le GPU NVIDIA Blackwell Ultra GB300, on trouve 160 multiprocesseurs streaming (SMs), chacun avec 128 cœurs CUDA, quatre cœurs Tensor de 5ème génération, et 256 Ko de mémoire Tensor. Cela se traduit par un impressionnant total de 20 480 cœurs CUDA et 640 cœurs Tensor.
| Caractéristiques | Hopper | Blackwell | Blackwell Ultra |
|---|---|---|---|
| Processus de fabrication | TSMC 4N | TSMC 4NP | TSMC 4NP |
| Transistors | 80B | 208B | 208B |
| Dies par GPU | 1 | 2 | 2 |
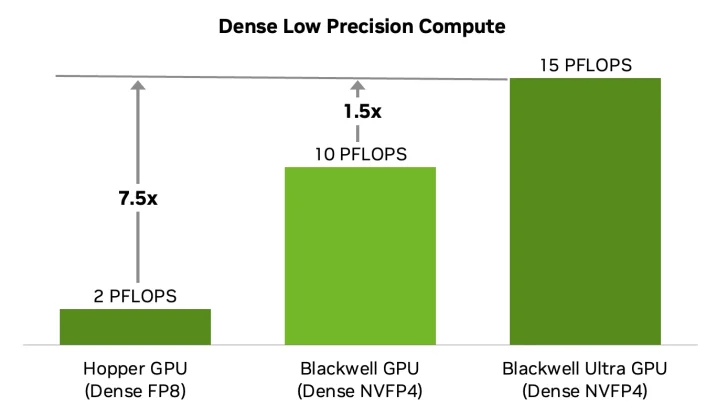
| Performance NVFP4 dense | sparse | – | 10 | 20 PetaFLOPS | 15 | 20 PetaFLOPS |
| Performance FP8 dense | sparse | 2 | 4 PetaFLOPS | 5 | 10 PetaFLOPS | 5 | 10 PetaFLOPS |
| Accélération d’attention (SFU EX2) | 4.5 TeraExponentials/s | 5 TeraExponentials/s | 10.7 TeraExponentials/s |
| Capacité max HBM | 80 Go HBM (H100) 141 Go HBM3E (H200) |
192 Go HBM3E | 288 Go HBM3E |
| Largeur de bande max HBM | 3.35 To/s (H100) 4.8 To/s (H200) |
8 To/s | 8 To/s |
| Largeur de bande NVLink | 900 Go/s | 1 800 Go/s | 1 800 Go/s |
| Puissance max (TGP) | Jusqu’à 700W | Jusqu’à 1 200W | Jusqu’à 1 400W |
Les cœurs Tensor de 5ème génération sont cruciaux pour les opérations de calcul en IA. NVIDIA a introduit d’importantes innovations à chaque génération de ces cœurs, parmi lesquelles :
- NVIDIA Volta : unités MMA à 8 fils, FP16 avec accumulation FP32.
- NVIDIA Ampere : MMA sur toute la largeur de la warp, formats BF16 et TensorFloat-32.
- NVIDIA Hopper : MMA dans le groupe de warp avec support FP8.
- NVIDIA Blackwell : 2ème génération d’Engine Transformer avec FP8, FP6, computation NVFP4, mémoire TMEM.
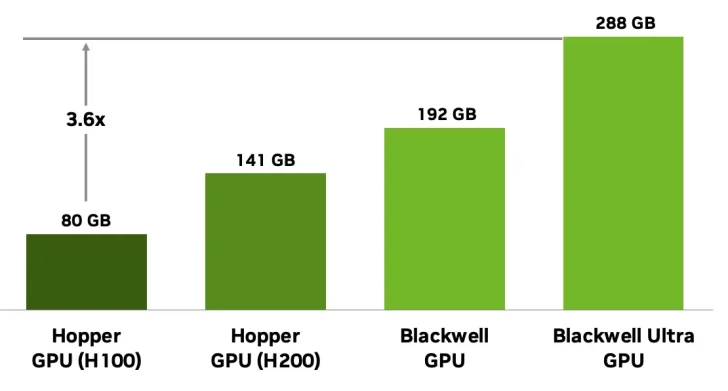
Le Blackwell Ultra dispose d’une mémoire considérablement améliorée, proposant 288 Go de HBM3e par rapport aux 192 Go des solutions Blackwell GB200. Cela permettra de prendre en charge des modèles d’IA à plusieurs trillions de paramètres. La mémoire, organisée en 8 piles, fonctionne à 8 To/s par GPU, offrant les fonctionnalités suivantes :
- Résidence complète du modèle : modèles de plus de 300 milliards de paramètres sans déchargement de mémoire.
- Longueurs de contexte étendues : capacité de cache KV plus grande pour les modèles transformateurs.
- Efficacité de calcul améliorée : rapports plus élevés de calcul à mémoire pour une variété de charges de travail.
Le Blackwell utilise le même interconnexion NVLINK que le NVLINK Switch et offre aussi un interface PCIe Gen6 x16 pour se connecter aux GPU hôtes. Voici quelques caractéristiques de connectivité NVLINK :
- Largeur de bande par GPU : 1,8 To/s bidirectionnel.
- Amélioration de performance : 2x supérieur au NVLink 4.
- Topologie maximale : 576 GPUs dans un tissu de calcul non-bloquant.
- Intégration à l’échelle du rack : 72 configurations NVL72 avec 130 To/s de bande passante agrégée.
- Interface PCIe : Gen6 × 16 voies.
- NVLink-C2C : communication CPU-GPU avec cohérence mémoire.
| Interconnexion | GPU Hopper | GPU Blackwell | GPU Blackwell Ultra |
|---|---|---|---|
| NVLink (GPU-GPU) | 900 | 1 800 | 1 800 |
| NVLink-C2C (CPU-GPU) | 900 | 900 | 900 |
| Interface PCIe | 128 (Gen 5) | 256 (Gen 6) | 256 (Gen 6) |
Grâce à cette architecture, le Blackwell Ultra GB300 parvient à réaliser une augmentation de 50 % de la sortie de calcul en utilisant le nouveau standard NVFP4. Ce modèle offre une précision proche de FP8, avec des différences souvent inférieures à 1 %. Cela réduit également l’empreinte mémoire de 1,8x par rapport à FP8.
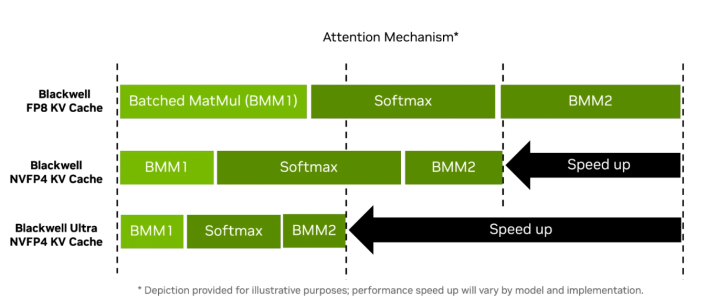
Le Blackwell Ultra bénéficie aussi d’une gestion avancée des travaux et de nouvelles fonctionnalités de sécurité adaptées à l’entreprise, telles que :
- Moteur GigaThread amélioré : ordonnanceur de travail de nouvelle génération offrant une meilleure performance de commutation de contexte.
- Multi-Instance GPU (MIG) : possibilité de partitionner les GPUs en instances de tailles différentes.
- Protection des données sensibles : fonctionnalités de sécurité pour les modèles d’IA et les données.
- Moteur de service d’attestation à distance : système de fiabilité équipé par IA pour surveiller des milliers de paramètres et optimiser les plannings de maintenance.
La Blackwell Ultra GB300 démontre sa capacité à délivrer une efficience supérieure, surpassant le modèle GB200. Ces avancées montrent qu’NVIDIA reste à la pointe de l’innovation en IA, soutenu par une forte recherche et développement qui continuera à se développer dans les années à venir.



