NVIDIA améliore Llama 3.1 de 1,9x grâce à l’algorithme de décodage Medusa

Dans le monde des accelerateurs d’IA, NVIDIA marque encore un coup avec son nouveau HGX H200. En intégrant l’algorithme de décodage exclusif « Medusa », les performances d’inférence pour le modèle Llama 3.1 explosent littéralement. Une avancée qui souligne l’importance de l’optimisation logicielle dans le développement de l’intelligence artificielle. Plongeons dans les innovations qui font de cette technologie un outil incontournable.
NVIDIA : vers une performance accrue grâce à Medusa
Les grands modèles linguistiques (LLM) prennent de l’ampleur et leur complexité augmente. Dans ce contexte, la puissance de calcul multi-GPU devient essentielle pour répondre aux exigences d’une IA générative en temps réel. Un travail d’équipe virtuel, où les GPUs collaborent comme une seule entité, est essentiel pour garantir une faible latence et un haut débit.
La clé de cette performance réside dans la capacité des GPU à traiter des requêtes simultanément. En utilisant des techniques comme le tensor parallelism et des algorithmes avancés tels que le speculative decoding, NVIDIA réussit à améliorer l’expérience utilisateur. Cela permet de réduire le temps nécessaire à la génération de réponses, rendant l’interaction plus fluide.

Medusa : une avancée dans la génération de tokens
Avec les modèles LLM basés sur des transformateurs, chaque token est généré de manière séquentielle. Ce processus, bien que précis, limite la vitesse de génération à un seul token par étape. L’algorithme de Medusa, lui, redéfinit cette approche en permettant de prédire plusieurs tokens simultanément, augmentant ainsi le débit de production.
En pratique, Medusa se sert de « têtes Medusa » pour prédire des tokens en parallèle, optimisant l’utilisation des ressources GPU. Grâce à cela, un système HGX H200 atteint des niveaux de performance impressionnants, avec une capacité de 268 tokens par seconde pour Llama 3.1 70B et 108 tokens par seconde pour Llama 3.1 405B.
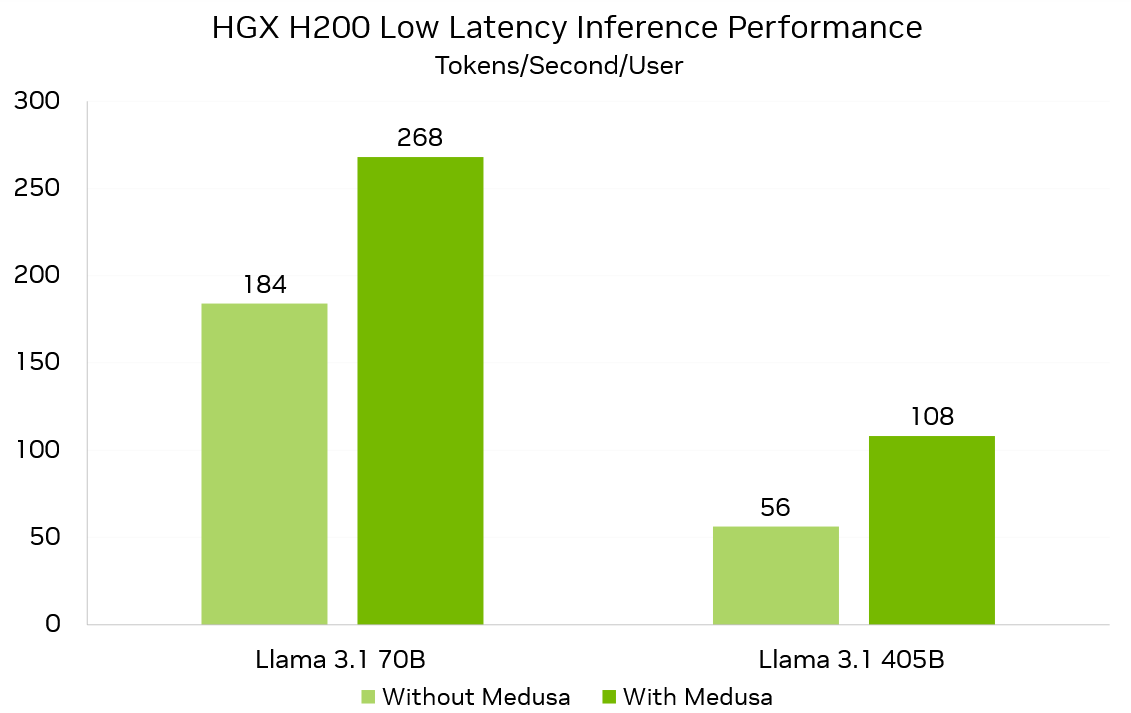
Avec ces nouvelles capacités, Medusa améliore les performances générales des modèles de Llama, atteignant jusqu’à 1.9x plus de rapidité. Les optimisations futures, réalisées avec les outils de NVIDIA, laissent présager encore plus d’innovations passionnantes à venir.
NVIDIA : un esprit d’innovation sans fin
NVIDIA, avec son HGX H200 et les technologies associées, offre une plateforme robuste pour le traitement en temps réel des LLM. L’innovation ne s’arrête pas là. Chaque couche de leur écosystème, des puces aux algorithmes, est continuellement améliorée pour maximiser les performances et réduire les coûts d’inférence.
Nous sommes impatients de découvrir les prochaines avancées dans ce domaine passionnant et l’impact qu’elles auront sur l’expérience utilisateur et l’intelligence artificielle en général. Quelle aventure facile et enrichissante que celle d’être témoin de ces progrès dans le paysage technologique !



