CoreWeave démontre 6X de performance GPU avec NVIDIA GB300 NVL72 contre H100 dans DeepSeek R1

Le dernier superchip AI de NVIDIA, le Blackwell, surpasse facilement le précédent GPU H100 en réduisant le parallélisme tensoriel, offrant ainsi un débit nettement plus élevé.
NVIDIA GB300 : Mémoire et Bande Passante Supérieures, Gains de Débit Significatifs Face au H100
Les superchips AI de NVIDIA, équipés par Blackwell, présentent des avantages considérables par rapport aux précédents GPU comme le H100. Le GB300 est déjà l’offre la plus performante de NVIDIA, fournissant des améliorations générationnelles en calcul ainsi qu’une capacité et une bande passante mémoire bien plus élevées, essentielles pour les charges de travail AI lourdes. Cela est confirmé par le dernier banc d’essai réalisé par CoreWeave, qui a constaté que la dernière plateforme de NVIDIA peut offrir un débit nettement plus élevé en réduisant le parallélisme tensoriel.
CoreWeave a testé les deux plateformes avec le modèle de raisonnement DeepSeek R1, qui est assez complexe. La différence majeure réside dans les configurations très distinctes. D’une part, un cluster de 16x NVIDIA H100 était nécessaire pour exécuter le modèle, tandis que, d’autre part, seulement 4x GB300 étaient requises sur l’infrastructure NVIDIA GB300 NVL72. Malgré l’utilisation d’un quart des GPU, le système basé sur le GB300 a fourni un débit brut 6 fois supérieur par GPU, démontrant l’énorme avantage des GPU dans les charges de travail AI complexes comparé au H100.
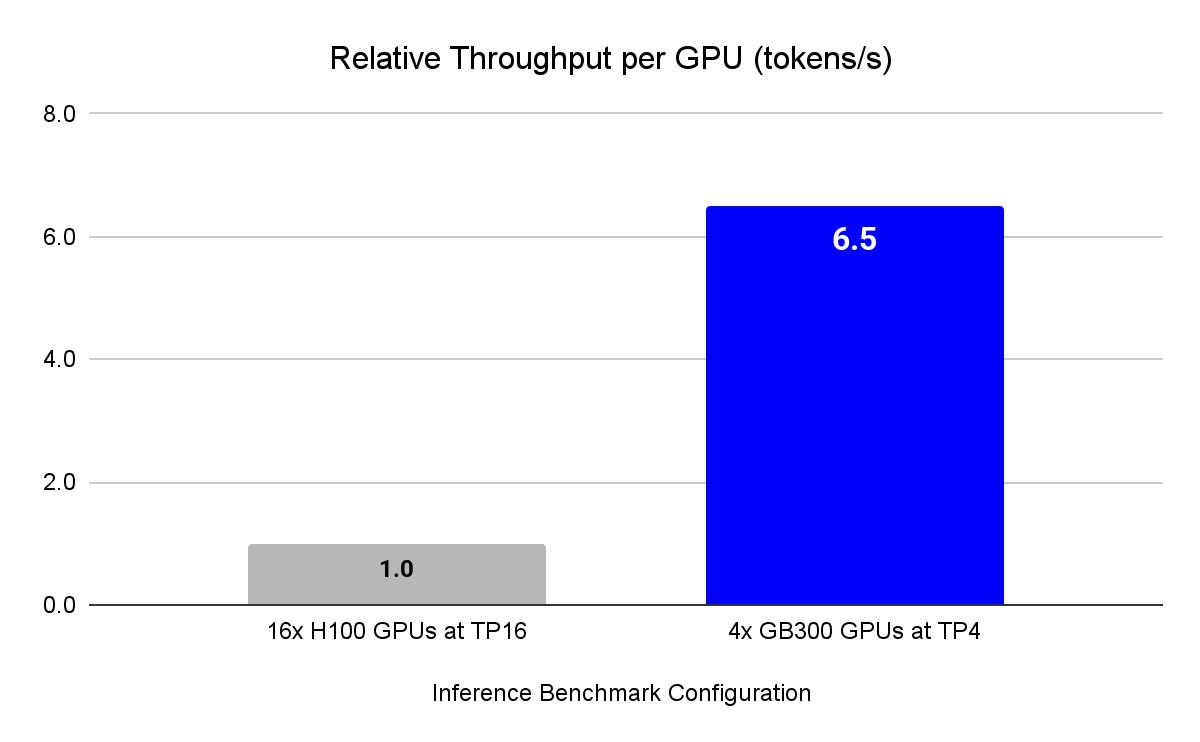
Il est évident que le GB300 bénéficie d’un grand avantage sur le système H100, car il permet d’exécuter le même modèle avec seulement 4 voies de parallélisme tensoriel. Grâce à une réduction des divisions, la communication inter-GPU est améliorée, et la capacité mémoire ainsi que la bande passante plus élevées jouent également un rôle crucial dans l’augmentation drastique de performances. Avec une telle avancée architecturale, la plateforme GB300 NVL72 s’annonce solide, grâce aux connexions haute bande passante NVLink et NVSwitch, permettant aux GPU d’échanger des données à des vitesses incroyables.
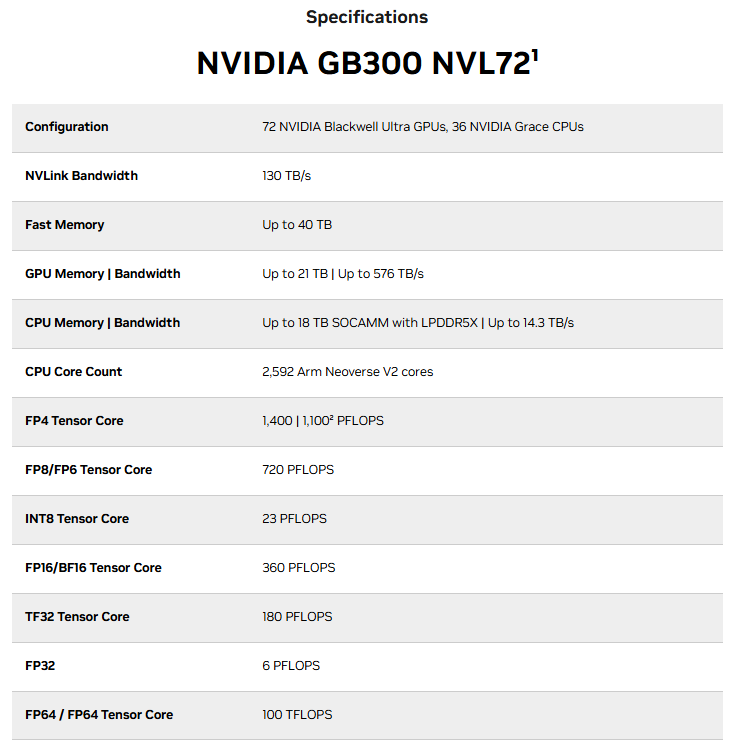
Pour les clients, cela indique une génération de tokens plus rapide et une latence réduite tout en favorisant une scalabilité plus efficace des charges de travail AI d’entreprise. CoreWeave met en avant les caractéristiques et fonctionnalités extraordinaires du système NVIDIA GB300 NVL72, qui offre une capacité mémoire énorme de 37 To (le GB300 NVL72 supporte jusqu’à 40 To) pour exécuter de grands modèles AI complexes, ainsi que des interconnexions ultra-rapides qui fournissent 130 To/s de bande passante mémoire.
En somme, le NVIDIA GB300 ne se limite pas à des TFLOPs bruts, mais met également l’accent sur l’efficacité. La réduction du parallélisme tensoriel permet au GB300 de minimiser la surcharge de communication entre les GPU, ce qui mène souvent à un bottleneck (goulots d’étranglement) pour l’entraînement et l’inférence AI à grande échelle. Avec le GB300, les entreprises peuvent désormais atteindre des débits bien plus élevés même avec moins de GPU, ce qui réduit non seulement les coûts globaux mais les aide aussi à évoluer efficacement.



