BitNet de Microsoft : l’IA révolutionne avec seulement 400 Mo et sans GPU !

Microsoft dévoile BitNet b1.58 2B4T, un modèle de langage innovant qui allie efficacité et performance. Avec sa méthode de quantification ternaire, il permet une utilisation optimale de la mémoire tout en offrant des résultats comparables à d’autres modèles de pointe, et ce, sur du hardware standard.
Microsoft a lancé BitNet b1.58 2B4T, un nouveau type de modèle de langage conçu pour une efficacité exceptionnelle. Contrairement aux modèles AI conventionnels qui reposent sur des nombres flottants de 16 ou 32 bits pour représenter chaque poids, BitNet n’utilise que trois valeurs dédiées : -1, 0, ou +1. Cette approche, connue sous le nom de quantification ternaire, permet de stocker chaque poids en seulement 1,58 bits. Le résultat est un modèle qui réduit considérablement l’utilisation de la mémoire et fonctionne beaucoup plus facilement sur du hardware standard, sans nécessiter les GPU haut de gamme habituellement requis pour l’AI à grande échelle.
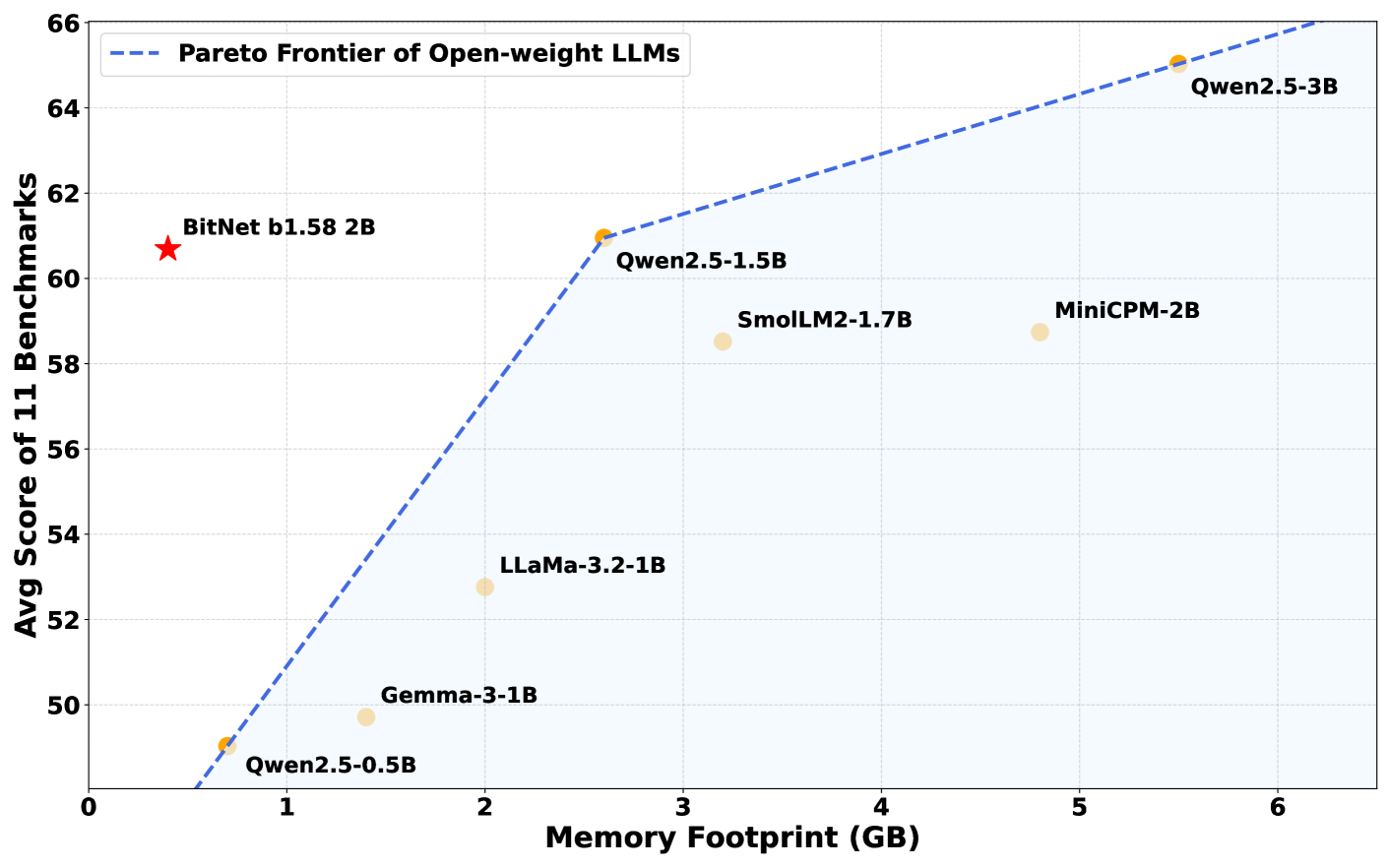
Le modèle BitNet b1.58 2B4T a été développé par le groupe General Artificial Intelligence de Microsoft et contient deux milliards de paramètres – des valeurs internes qui permettent au modèle de comprendre et de générer du langage. Pour compenser ses poids à faible précision, le modèle a été entraîné sur un jeu de données massif de quatre trillions de tokens, équivalant à environ 33 millions de livres. Cet entraînement extensif permet à BitNet d’offrir des performances comparables – voire supérieures dans certains cas – à d’autres modèles de taille similaire, tels que Llama 3.2 1B de Meta, Gemma 3 1B de Google et Qwen 2.5 1.5B d’Alibaba.
Lors de tests de référence, BitNet b1.58 2B4T a démontré une bonne performance sur diverses tâches, y compris des problèmes de mathématiques de l’école primaire et des questions nécessitant un raisonnement de bon sens. Dans certaines évaluations, il a même surclassé ses concurrents.
Ce qui distingue vraiment BitNet, c’est son efficacité mémoire. Le modèle nécessite seulement 400 Mo de mémoire, soit moins d’un tiers de ce que demandent généralement les modèles comparables. En conséquence, il peut fonctionner sans problème sur des CPU standards, y compris la puce M2 d’Apple, sans avoir recours à des GPU haut de gamme ou à du hardware AI spécialisé.
Ce niveau d’efficacité est rendu possible grâce à un cadre logiciel personnalisé appelé bitnet.cpp, optimisé pour profiter pleinement des poids ternaires du modèle. Ce cadre garantit des performances rapides et légères sur les appareils informatiques quotidiens.
Les bibliothèques AI standard comme les Transformateurs de Hugging Face ne proposent pas les mêmes avantages de performance que BitNet b1.58 2B4T, rendant l’utilisation du cadre personnalisé bitnet.cpp indispensable. Disponible sur GitHub, le cadre est actuellement optimisé pour les CPU, mais un support pour d’autres types de processeurs est prévu dans les mises à jour futures.
L’idée de réduire la précision des modèles pour économiser de la mémoire n’est pas nouvelle, les chercheurs ayant longtemps exploré la compression des modèles. Cependant, la plupart des tentatives passées consistaient à convertir des modèles à pleine précision après l’entraînement, souvent au prix de la précision. BitNet b1.58 2B4T adopte une approche différente : il est entraîné dès le départ en n’utilisant que trois valeurs de poids (-1, 0 et +1). Cela lui permet d’éviter de nombreuses pertes de performances observées dans les méthodes antérieures.
Ce changement a des implications considérables. Faire fonctionner de grands modèles AI nécessite généralement un hardware puissant et une énergie considérable, des facteurs qui augmentent les coûts et l’impact environnemental. Comme BitNet repose sur des calculs extrêmement simples – principalement des additions plutôt que des multiplications – il consomme beaucoup moins d’énergie.
Les chercheurs de Microsoft estiment qu’il utilise 85 à 96 % moins d’énergie que des modèles à pleine précision comparables. Cela pourrait ouvrir la voie à l’exécution d’AI avancées directement sur des appareils personnels, sans avoir besoin de superordinateurs basés dans le cloud.
Cependant, BitNet b1.58 2B4T présente certaines limites. Il prend actuellement en charge seulement des matériels spécifiques et nécessite le cadre personnalisé bitnet.cpp. Sa fenêtre de contexte – la quantité de texte qu’il peut traiter à la fois – est plus petite que celle des modèles les plus avancés.
Les chercheurs continuent d’étudier pourquoi le modèle fonctionne si bien avec une architecture simplifiée. Les travaux futurs visent à étendre ses capacités, y compris le support de davantage de langues et d’entrées textuelles plus longues.



