AMD présente la première carte réseau AI NIC Pensando Pollara 400 UEC prête à offrir des vitesses de 400GbE

La toute nouvelle Pensando Pollara 400 AI NIC d’AMD, le premier AI NIC prêt pour le UEC, a été détaillée lors de Hot Chips 2025.
AMD Augmente de 25% les Performances Avec Son AI NIC Pensando Pollara 400
L’année dernière, AMD a présenté sa dernière solution réseau, la Pensando Pollara 400, un NIC développé pour les systèmes d’IA. Ce NIC est également le premier du secteur à être prêt pour le UEC ou Ultra Ethernet Consortium. En termes de bande passante, la vitesse de 400 Gbps correspond à celle de la solution ConnectX-7 de NVIDIA, mais avec une solution ConnectX-8 plus haut de gamme offrant des vitesses de 800GbE.

Parmi les principales caractéristiques de la Pensando Pollara, on trouve :
- Pipelines matériels programmables
- Up to 1,25x performance boost
- 400 Gbps
- Écosystème ouvert
- UEC Ready RDMA
- Réduction des temps d’achèvement des tâches
- Haute disponibilité
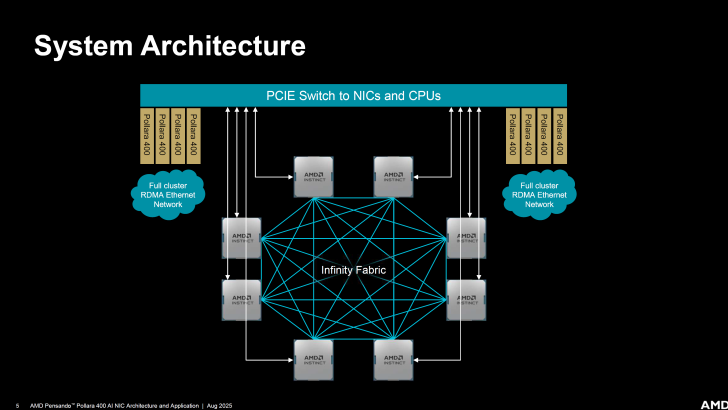
Les solutions de mise en réseau Pensando sont conçues en accord avec d’autres solutions pour centres de données d’AMD, telles que les familles EPYC et Instinct. L’entreprise utilise des commutateurs PCIe qui se connectent aux NIC et aux CPU.

Le Pensando NIC lui-même ne dispose d’aucun Switch PCIe et se connecte à une interface Gen5 x16. Voici le diagramme bloc :
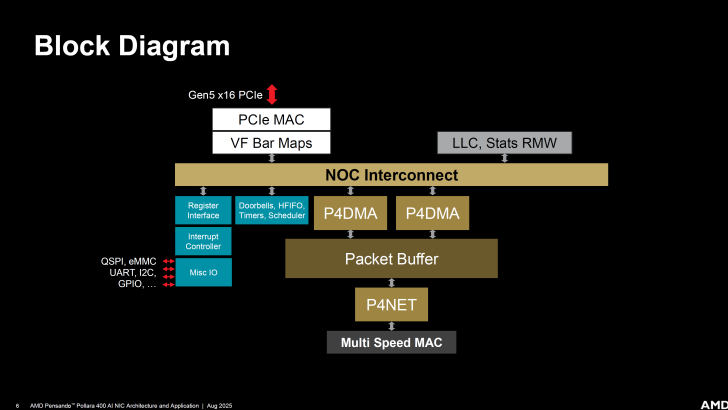
AMD s’appuie sur une architecture P4 pour son AI NIC Pensando Pollara 400.
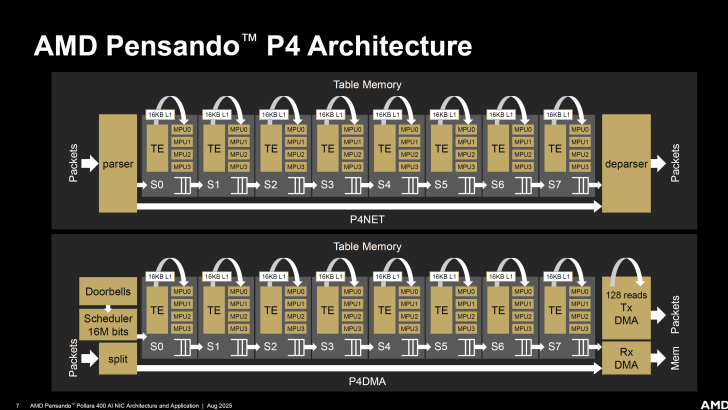
Certains des principaux composants du pipeline P4 incluent le Table Engine (TE), qui génère des clés de table à partir d’un vecteur d’en-tête de paquet, d’un hachage, ou directement. Il émet également des lectures mémoire en fonction du type.

L’architecture P4 inclut également une Match Processing Unit (MPU), qui est un processeur spécifique avec des opcodes efficaces pour manipuler des champs, offrant des interfaces distinctes pour la mémoire, la table et le PHV.
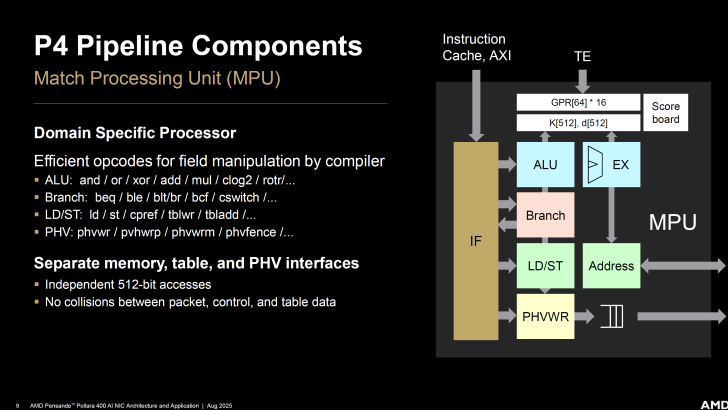
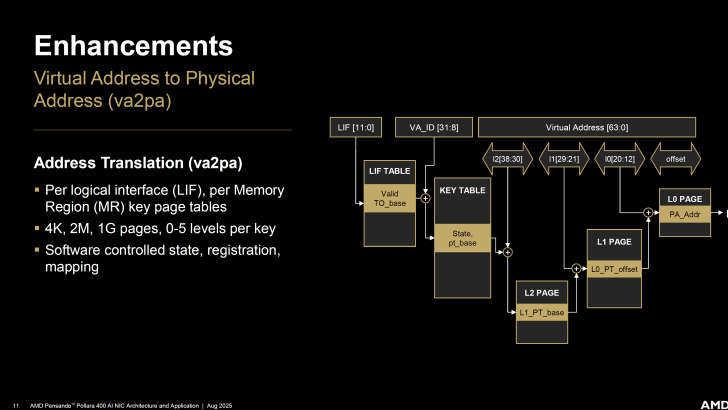
Quelques améliorations incluent la traduction d’adresses de Virtual Address to Physical Address (va2pa).
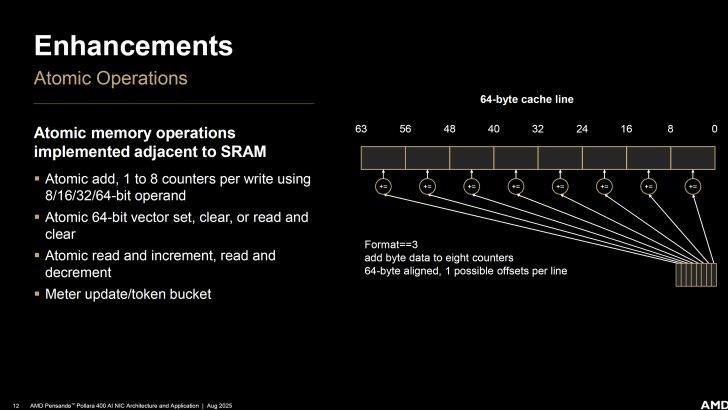
Des opérations mémoire atomiques ont également été mises en œuvre à proximité de la SRAM.
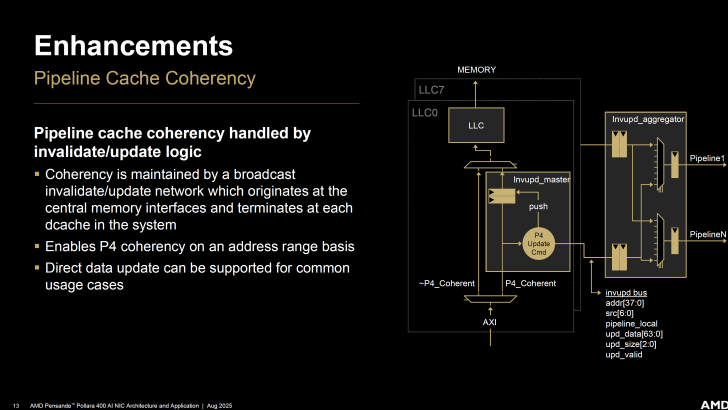
La cohérence du cache du pipeline est gérée par une logique d’invalidation/mise à jour, permettant une cohérence P4 sur une base de plage d’adresses.
AMD partage également des défis pour améliorer les performances des systèmes d’IA sur les réseaux à échelle. Ces défis incluent une mauvaise utilisation des liens provenant de l’équilibrage de charge ECMP, ainsi que la congestion du réseau et des nœuds.

Les réseaux d’IA affichent des taux d’utilisation du réseau plus élevés que les réseaux généralistes, saturant souvent toute la bande passante. AMD discute de certains de ces défis et de leurs solutions.
La principale solution à ces défis réside dans l’adoption de l’UEC ou Ultra Ethernet Consortium, qui est une architecture ouverte, interopérable, hautes performances, et un empilement complet de communications pour répondre aux exigences de mise en réseau des IA et HPC à grande échelle. Elle est performante, évolutive et rentable.
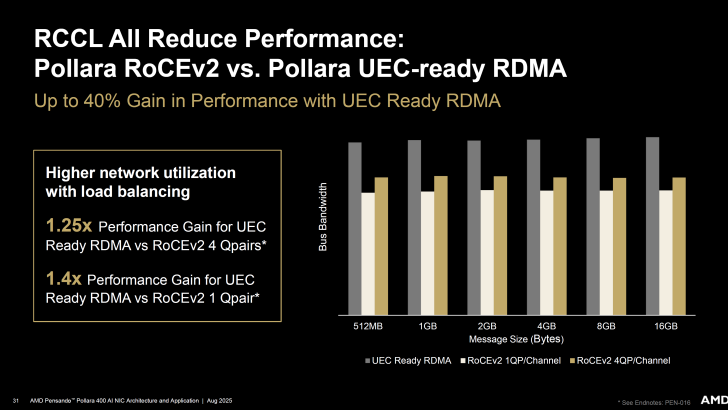

Le NIC RDMA AI Pensando Pollara 400 d’AMD offre un gain de performance de 25% par rapport à RoCEv2 avec 4 Qpairs et une amélioration de 40% par rapport à RoCEv2 avec 1 Qpair.



