AMD explore le stacking du cache L2 sur ses futurs GPU pour réduire la latence des designs classiques

Dans une récente étude, AMD examine des méthodes pour empiler la mémoire cache L2 sur ses futurs processeurs, avec une latence similaire ou améliorée.
AMD et la technologie de cache L2 empilé
La société a publié un document de recherche intitulé « Balanced Latency Stacked Cache », accompagné du numéro de brevet « US20260003794A1 ». Ce document décrit des techniques pour un système de cache empilé avec une mémoire cache de première couche et au moins une seconde en orientation empilée.
AMD a déjà intégré un cache empilé avec la technologie 3D V-Cache, ajoutant une couche de cache L3. La première génération de 3D V-Cache était placée au-dessus des chiplets Zen, tandis que la seconde génération se situe en dessous. Ces techniques illustrent une stratégie pour améliorer les performances à travers une hiérarchie de cache efficace.

L’innovation à travers l’empilement
Dans sa recherche sur le cache L2 empilé, AMD présente un exemple illustratif. Il met en avant une structure de base associée à un die de calcul et à un die de cache, puis un autre die de calcul et de cache est ajouté au-dessus. Ce module cache utilise quatre régions de 512 Ko pour un total de 2 Mo de cache L2, extensible jusqu’à 4 Mo.
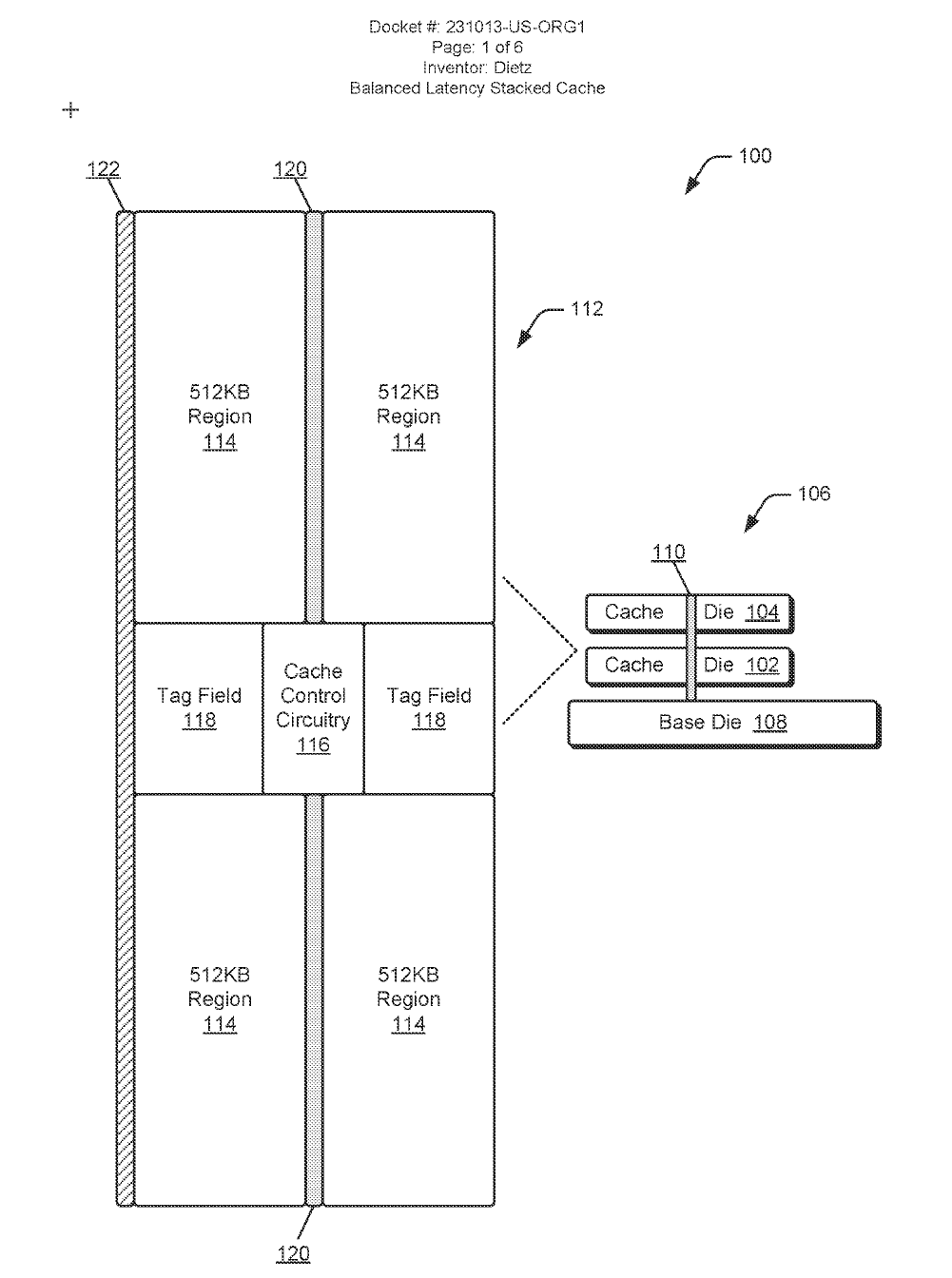
Le système adopte le principe de la 3D V-Cache avec des liaisons verticales entre les différentes couche, utilisant des vias en silicium. Selon AMD, cette méthode permet de réduire la latence des requêtes d’accès au cache tout en offrant des économies d’énergie.
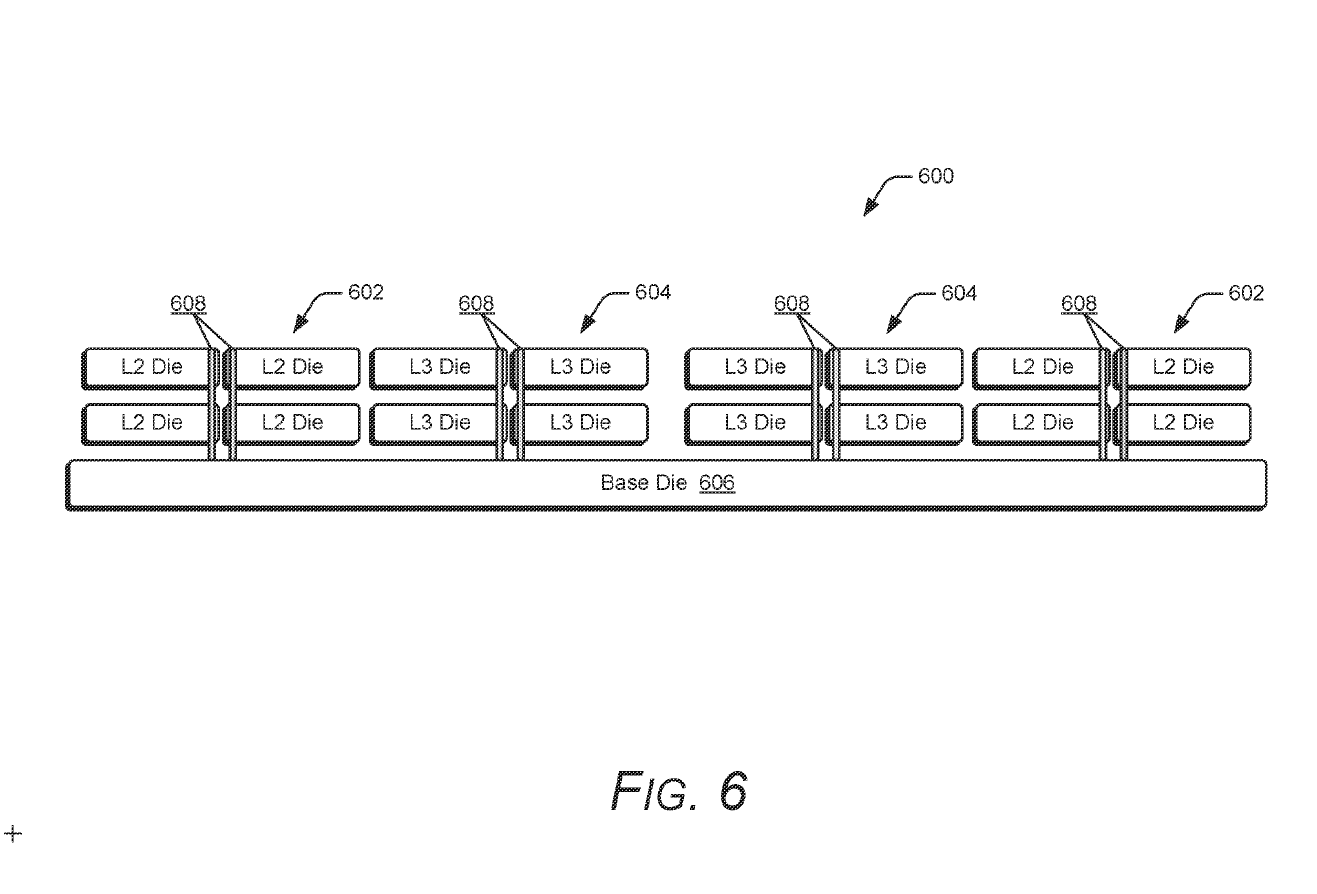
Les résultats indiquent qu’un cache L2 empilé peut avoir une latence de 12 cycles, contre 14 pour un cache planaire standard. Ce développement pourrait renforcer la position d’AMD face à la concurrence en offrant des performances supérieures avec des économies d’énergie significatives.
Bien que la disponibilité des caches L2 empilés sur des modèles réels soit encore à déterminer, cette avancée pourrait transformer les futurs processeurs et GPU d’AMD.




