AMD-135 : premier petit modèle de langage de la société, vise un décodage spéculatif

La société AMD a récemment annoncé le lancement de son tout premier modèle de langage réduit, le AMD-135M, qui intègre une technologie de décodage spéculatif pour optimiser les capacités d’intelligence artificielle. Ce développement volumineux pourrait transformer les processus technologiques en facilitant des performances plus efficaces.
Le Modèle AMD-135M : Un Pas en Avant dans l’Espace des Modèles de Langage
Dans un secteur où des modèles de langage de grande envergure comme GPT-4 et Llama dominent, les modèles de langage réduits commencent à jouer un rôle crucial. Le AMD-135M prouve que ces modèles plus petits peuvent offrir des avantages distincts, en se concentrant sur des cas d’utilisation spécifiques et remarquables.
Caractéristiques du AMD-135M
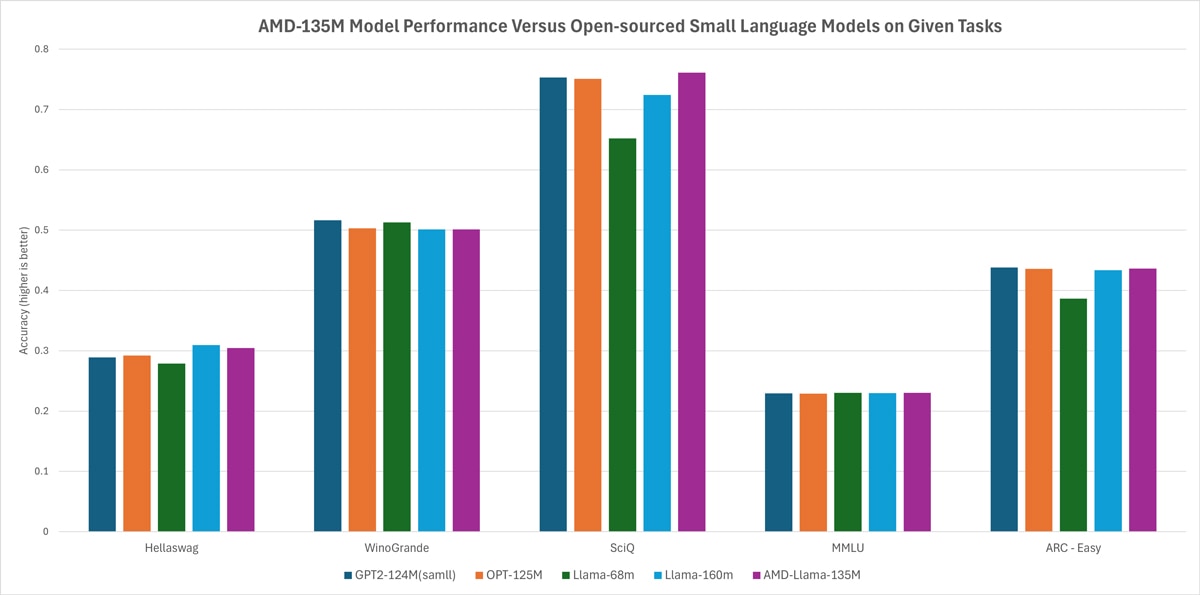
Le AMD-135M a été conçu entièrement à partir de zéro, s’appuyant sur des accélérateurs AMD Instinct™ MI250. Ce modèle a intégré 670 milliards de tokens, et se décline en deux versions : AMD-Llama-135M et AMD-Llama-135M-code, chacune ayant ses propres spécificités.
- Préentraînement : Le modèle AMD-Llama-135M a nécessité six jours d’entraînement intensif avec 670 milliards de tokens de données variées, utilisant quatre nœuds MI250.
- Ajustement du Code : La déclinaison AMD-Llama-135M-code a fait l’objet d’un affinage avec 20 milliards de tokens supplémentaires relatifs au code, prenant également quatre jours.
Ce modèle propose un accès facilité aux code, jeu de données et poids, permettant aux développeurs de le reproduire et d’explorer d’autres formations de SLM et LLM.
Technologie de Décodage Spéculatif : Une Révolution dans les Modèles de Langage
Contraire aux approches autorégressives qui limitent la sortie à un seul token à la fois, le décodage spéculatif améliore considérablement l’efficience d’accès à la mémoire. Ce processus permet d’extraire plusieurs tokens simultanément, ce qui accélère le temps d’inférence tout en préservant la performance système.
Ce nouveau mécanisme a conduit à des gains significatifs en termes de vitesse. En utilisant le modèle AMD-Llama-135M-code comme modèle de brouillon pour le CodeLlama-7b, des tests sur l’accélérateur MI250 ainsi que sur les processeurs Ryzen™ AI ont montré des améliorations notables.
Des Performances d’Inférence Accrues sur Divers Matériels
Les tests d’inférence sur le modèle AMD-Llama-135M-code ont révélé une amélioration substantielle de la vitesse sur plusieurs plateformes de hardware AMD. Ces résultats soulignent non seulement l’efficacité du modèle en environnement de centre de données, mais aussi son adaptabilité pour des applications de bureau AI, prouvant son potentiel polyvalent.
En résumé, le AMD-135M représente un tournant dans la conception des modèles de langage, encourageant une approche plus inclusive et éthique dans le développement d’IA. Avec des performances optimisées, ce modèle pourrait ouvrir la voie à de futures innovations notez la collaboration accrue pour relever les défis que cette technologie représente.



